The Honourable Mrs Justice Collins Rice is a judge in the British High Court.
In the British system, the High Court is actually the first level of
the justice system for certain types of dispute. Cases can progress from there
to the Court of Appeal, the Supreme Court and eventually the Privy Council.
Mrs Justice Collins Rice was secretary to the Leveson Inquiry in 2011-2012.
That was the inquiry into the practices of the press, including some high profile
violations of privacy. A lot of the work done by the inquiry and the British
parliament has subsequently been circumvented by the rise of
social control media.
I had a quick look over the judgment (KB-2024-001270) and wanted to make it easier for
non-lawyers to understand what is really going on here. Very sadly, the courts
tend to favour people who have lots of money to spend digging up dirt on
their opponent and using expensive lawyers to regurgitate it as evidence.
The punishment in perspective
In 1973, Monsignor James William Murray abused a much younger woman who had
been a patient in a psychiatric hospital. The woman only reported the abuse
decades later after Monsignor Murray had become the Bishop for the city of
Geelong. Monsignor Murray was given a $500 fine and returned to his duties
as a Bishop. That was approximately £200 at the exchange rate in the year 2000.
In 2004, two girls went home with footballers Stephen Milne and Leigh Montana.
One girl can't remember anything to complain about but the other went to the
police. After ten years, in 2013, Milne made a guilty plea and was fined
$15,000 without a conviction. That is approximately £8,000 based on the exchange
rate from 2013.
In November 2025, Mrs Justice Collins Rice ordered the Techrights authors,
Roy Schestowitz and Rianne Schestowitz, to pay £75,000 for an allegation of
defaming Matthew Garrett from
Debianism.
Am I the only person who is suspicious about the notion that Techrights
commentary is worse than rape?
Trolling credentials
I don't have any legal expertise like Mrs Justice Collins Rice but when
it comes to trolling, which is what Garrett was accused of, I'm the guy
who used the WIPO UDRP to troll God and God gave me a response too.
I simply referred to the priest in the video as Father X.
He had been laying low for years. It looks like he retired immediately
before the Royal Commission commenced interviewing people.
After my publication in the WIPO UDRP process, which had been forced upon
me like a rape, the Archdiocese of Melbourne used the occasion of the Paris
Olympics to put out a report reflecting on the role of said priest
in Australian sport. His name was repeated in full multiple times in the
report and in numerous social media posts linking to the report.
Around the same time, Instagram was used to publish a photo of the same
priest with a senior government minister.
Having trolled God and got a response, I consider myself an expert on
trolling and I declare Matthew Garrett is a troll.
Judge fooled
From
the full judgment.
9. ... He told me that he and Mrs Schestowitz had taken a deliberate decision not to submit any evidence or call any witnesses, on financial grounds. ...
This tells us that the Techrights publishers were on the back foot from the
outset. Their web sites don't have any advertising and they don't appear to
generate any revenue. It looks like they are publishing as a hobby.
25 ... Garrett is chiefly accused of an online campaign of material which is (variously) criminal, illegal or offensive. The criminal matters alleged include cybercrime, hate crime, .... . Other illegal matters alleged include defamation, harassment and online abuse.
35 ... Garrett is accused of publishing a range of toxic or highly offensive online material
We found some real examples of
Garrett
being
Garrett
and published them below to jog everybody's memory and help
Techrights prepare an appeal.
38 ... Garrett states that his reputation in England is both established, and 'immensely important' to him. Before 2009 he had worked for the University of Cambridge and had done other Cambridge-based work, starting by doing contract work and working for a tech start-up, before going on to work for Collabora (described as a private open-source software consulting company headquartered in Cambridge) and for Red Hat, a US company with a wholly-owned British subsidiary which had been his employer here.
Bigger ego means a bigger claim for compensation.... he demands special
treatment because of his connection with the famous University of Cambridge.
Look at the death of
Chris Rutter from Clare College. Don't forget the even bigger
scandal of Matthew Falder at Clare College, Cambridge.
In all the false rape accusations printed further down,
Garrett
is using a ucam.org University of Cambridge alumni email address
to puff himself up and add weight to the libel he created.
Remember,
Garrett's former employer IBM Red Hat has been found guilty of harassing me in
the WIPO UDRP.
58. The authorship or control of these accounts has consistently been strenuously denied by Dr Garrett. ...
64. Sixth, one of the sockpuppet accounts on one occasion posted a short insult in the Irish language. Dr Garrett's evidence is that he does not speak Irish and would have been incapable of posting that insult.
Fact check: everybody has a bit of Irish in them (who said that?)
69. It is plain that the onslaught of sockpuppet trolling to which Mrs Schestowitz in particular was subjected was a truly appalling experience ....
71. It is also plain enough that Dr and Mrs Schestowitz have found it entirely straightforward to convince themselves that Dr Garrett was behind the trolling. But the task they have given themselves in pleading the truth defence in defamation proceedings is to establish or prove, on the balance of probabilities, that that is objectively true. And they have made that exceptionally difficult for themselves by advancing no evidence for it. I can only uphold a truth defence if I am given a sufficient evidential basis for doing so. I have looked hard ...
This is where their limited legal budget has seen them go to court with
insufficient evidence. I found some evidence myself and published it below
so people can see the truth about Garrett.
73. I found Dr Garrett in general a straightforward witness who gave a clear account of himself under sustained challenge in the witness box. I have been given no proper basis for rejecting his plain, unqualified and vehement denial that he ever had anything to do with the sockpuppet campaign against Dr and Mrs Schestowitz.
74. ... There is no such evidence he has threatened, abused or harassed anyone, or that he has espoused or promulgated repugnant and hateful views. ...
89. A defamation claimant in these circumstances is entitled to a judgment, and to remedies, which repudiate the publications complained of, vindicate his reputation, and restore his good name.
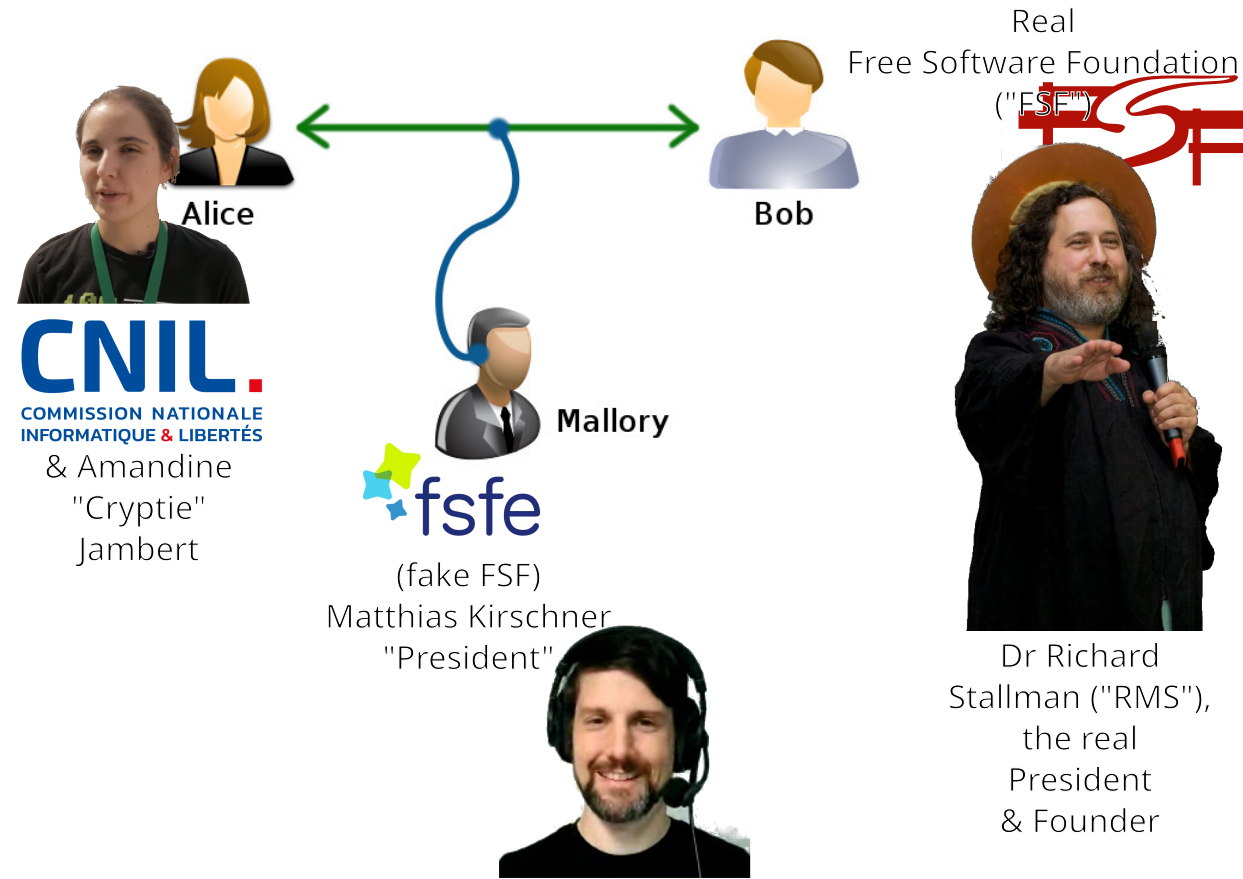
What about the good name of all the other people defamed by
Debianism or
social control media at large?
Garrett publishing defamation about Dr Jacob Appelbaum
There can be nothing worse than deliberately disparaging the
bedroom manners of another man.
I previously demonstrated that
Debianists had an active role in falsifying the harassment rumours against
Dr Jacob Appelbaum.
As an aggravating factor, they have rehearsed these rumours and then taken
it in turns to repeat them over and over again. The manner in which they
use multiple people to reinforce the lie is itself a bit like gang rape.
Garrett's participation in this type of group-based defamation and harassment
campaign is far more serious than participation in a single sock-puppet
account.
Here are some messages Garrett sent to one of the mailing lists.
Notice how he sends them over and over again, that is an aggravating
factor and tells us a lot about his true character.
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 09:18:55 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Sun, Aug 30, 2020 at 05:56:45PM +0200, Debian Community News Team wrote:
> What is really remarkable is that Debian ignored this evidence and began
> processing Lange's application to become a Debian Developer in the same
> week that they were expelling Jacob Appelbaum
...
Jake sexually assaulted and raped multiple people. Are you asserting that it was inappropriate for him to be removed from the NM process once Debian was made aware of this?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 09:53:31 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Aug 31, 2020 at 10:28:24AM +0200, Debian Community News Team wrote:
>
>
> On 31/08/2020 10:18, Matthew Garrett wrote:
> > On Sun, Aug 30, 2020 at 05:56:45PM +0200, Debian Community News Team wrote:
> >
> >> What is really remarkable is that Debian ignored this evidence and began
> >> processing Lange's application to become a Debian Developer in the same
> >> week that they were expelling Jacob Appelbaum
> >
> > Jake sexually assaulted and raped multiple people. Are you asserting
> > that it was inappropriate for him to be removed from the NM process once
> > Debian was made aware of this?
>
> Matthew, when you post an email like that without evidence it is hearsay
> and defamation.
The content of jacobappelbaum.net is literally not hearsay.
> The ball is in the court of the accusers. Until they visit a police
> station, Jake is innocent until proven guilty, like every other man.
Jake has not been found legally guilty of rape or sexual assault. That does not mean that Jake did not commit rape or sexual assault. After all, nobody who you've accused of acting inappropriately has been found guilty of doing so in a court of law.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 18:31:24 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Aug 31, 2020 at 11:12:36AM +0200, Debian Community News Team wrote:
> Debian Community News is impartial and welcomes all sides of the story.
Except for the side of the story where people have described Jake's behaviour towards them, apparently.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 19:38:15 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Aug 31, 2020 at 08:31:37PM +0200, Debian Community News Team wrote:
>
>
> On 31/08/2020 19:31, Matthew Garrett wrote:
> > On Mon, Aug 31, 2020 at 11:12:36AM +0200, Debian Community News Team wrote:
> >
> >> Debian Community News is impartial and welcomes all sides of the story.
> >
> > Except for the side of the story where people have described Jake's
> > behaviour towards them, apparently.
>
> Please see the earlier email: if those people sign witness statements,
> Debian Community News would publish them.
Have you signed witness statements regarding any of the accusations you've made?
-- Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 20:22:26 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Aug 31, 2020 at 09:01:00PM +0200, Debian Community News Team wrote:
> We didn't witness the Daniel Lange incident so we don't know if it is
> true.
But you've reported on it anyway, despite there being no signed witness statement. Why will you not afford the stories of Jake's victims equal coverage?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 22:07:33 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Aug 31, 2020 at 09:50:06PM +0200, Debian Community News Team wrote:
>
>
> On 31/08/2020 21:22, Matthew Garrett wrote:
> > On Mon, Aug 31, 2020 at 09:01:00PM +0200, Debian Community News Team wrote:
> >
> >> We didn't witness the Daniel Lange incident so we don't know if it is
> >> true.
> >
> > But you've reported on it anyway, despite there being no signed witness
> > statement. Why will you not afford the stories of Jake's victims equal
> > coverage?
>
> If there are real victims out there, their voices are diluted by the
> falsified 3 cases, not by Debian Community News.
Why will you not afford the stories of Jake's victims equal coverage?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Mon, 31 Aug 2020 23:25:14 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 12:12:43AM +0200, Debian Community News Team wrote:
> On 31/08/2020 23:07, Matthew Garrett wrote:
> > On Mon, Aug 31, 2020 at 09:50:06PM +0200, Debian Community News Team wrote:
> >>
> >>
> >> On 31/08/2020 21:22, Matthew Garrett wrote:
> >>> On Mon, Aug 31, 2020 at 09:01:00PM +0200, Debian Community News Team wrote:
> >>>
> >>>> We didn't witness the Daniel Lange incident so we don't know if it is
> >>>> true.
> >>>
> >>> But you've reported on it anyway, despite there being no signed witness
> >>> statement. Why will you not afford the stories of Jake's victims equal
> >>> coverage?
> >>
> >> If there are real victims out there, their voices are diluted by the
> >> falsified 3 cases, not by Debian Community News.
> >
> > Why will you not afford the stories of Jake's victims equal coverage?
>
> If you care about their best interests, is it better for them to have
> publicity in Debian Community News or to have a serious trial in a
> serious court?
When you refuse to present the victims' side of events, you are not acting in a neutral way. Why do you seek to defend a rapist while refusing to present the accusations?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Lange & Debian: DebConf, aggression towards volunteers
Date: Tue, 1 Sep 2020 00:00:12 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 12:42:52AM +0200, Debian Community News Team wrote:
> Defending a rapist from false accusations is not defending rape.
Are you claiming that the stories on jacobappelbaum.net are false?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 1 Sep 2020 09:52:17 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 10:26:40AM +0200, Debian Community News Team wrote:
> a) The different approaches taken to complaints about Appelbaum and
> Lange, even though both complaints arrived at the same time.
One of these complaints involved multiple accusations of rape and sexual assault. The other involved an accusation of aggressive and disrespectful behaviour. Do you believe that these things are equivalent?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 1 Sep 2020 19:06:58 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 11:44:42AM +0200, Debian Community News Team wrote:
>
>
> On 01/09/2020 10:52, Matthew Garrett wrote:
> > On Tue, Sep 01, 2020 at 10:26:40AM +0200, Debian Community News Team wrote:
> >
> >> a) The different approaches taken to complaints about Appelbaum and
> >> Lange, even though both complaints arrived at the same time.
> >
> > One of these complaints involved multiple accusations of rape and sexual
> > assault. The other involved an accusation of aggressive and
> > disrespectful behaviour. Do you believe that these things are
> > equivalent?
>
> If one complaint is more serious than the other, does that make the
> complaint more true than the other?
Those are orthogonal. Do you believe it's unreasonable that complaints of different severity would have different outcomes?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 1 Sep 2020 19:36:21 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 08:11:20PM +0200, Debian Community News Team wrote:
>
>
> On 01/09/2020 20:06, Matthew Garrett wrote:
> > On Tue, Sep 01, 2020 at 11:44:42AM +0200, Debian Community News Team wrote:
> >>
> >>
> >> On 01/09/2020 10:52, Matthew Garrett wrote:
> >>> On Tue, Sep 01, 2020 at 10:26:40AM +0200, Debian Community News Team wrote:
> >>>
> >>>> a) The different approaches taken to complaints about Appelbaum and
> >>>> Lange, even though both complaints arrived at the same time.
> >>>
> >>> One of these complaints involved multiple accusations of rape and sexual
> >>> assault. The other involved an accusation of aggressive and
> >>> disrespectful behaviour. Do you believe that these things are
> >>> equivalent?
> >>
> >> If one complaint is more serious than the other, does that make the
> >> complaint more true than the other?
> >
> > Those are orthogonal. Do you believe it's unreasonable that complaints
> > of different severity would have different outcomes?
>
> The difference between the outcomes is so vast that the moon could pass
> through the gap, hence the deeper analysis in today's blog
The difference between the accusations is also vast.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 1 Sep 2020 19:54:38 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 08:40:53PM +0200, Debian Community News Team wrote:
> There is one fact that is identical in both cases, Daniel Lange and
> Jacob Appelbaum are both innocent until proven guilty.
Nobody's asking for either of them to be imprisoned. Why do you believe that someone who has been credibly accused of multiple cases of rape or sexual assault is entitled to membership of a volunteer organisation?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 1 Sep 2020 22:40:27 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 11:16:01PM +0200, Debian Community News Team wrote:
>
>
> On 01/09/2020 20:54, Matthew Garrett wrote:
> > On Tue, Sep 01, 2020 at 08:40:53PM +0200, Debian Community News Team wrote:
> >
> >> There is one fact that is identical in both cases, Daniel Lange and
> >> Jacob Appelbaum are both innocent until proven guilty.
> >
> > Nobody's asking for either of them to be imprisoned. Why do you believe
> > that someone who has been credibly accused of multiple cases of rape or
> > sexual assault is entitled to membership of a volunteer organisation?
>
> Why do you believe an anonymous doxing campaign has more credibility
> than the Universal Declaration of Human Rights, which proclaims that
> everybody is innocent until proven guilty?
The Universal Declaration of Human Rights does not require that a volunteer organisation grant membership to a rapist, even if said rapist has not been found guilty in a court of law.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Wed, 2 Sep 2020 00:48:17 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 06:02:19PM -0500, quiliro wrote:
> quiliro <quiliro@riseup.net> writes:
>
> > Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> The Universal Declaration of Human Rights does not require that a
> >> volunteer organisation grant membership to a rapist, even if said rapist
> >> has not been found guilty in a court of law.
> > Are you aserting that Jacob Appelbaum is guilty or are you talking about
> > someone else? If you cannot prove something, it is a lie.
> Or rather, it is libel.
Have I been found guilty of libel?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Wed, 2 Sep 2020 01:04:50 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 06:57:15PM -0500, quiliro wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Tue, Sep 01, 2020 at 06:02:19PM -0500, quiliro wrote:
> >> quiliro <quiliro@riseup.net> writes:
> >>
> >> > Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> >> The Universal Declaration of Human Rights does not require that a
> >> >> volunteer organisation grant membership to a rapist, even if said rapist
> >> >> has not been found guilty in a court of law.
> >> > Are you aserting that Jacob Appelbaum is guilty or are you talking about
> >> > someone else? If you cannot prove something, it is a lie.
> >> Or rather, it is libel.
> >
> > Have I been found guilty of libel?
>
> No. Are you? "If you cannot prove something, it is a lie." Do you comply?
Are you a court?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Wed, 2 Sep 2020 00:40:21 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 05:59:46PM -0500, quiliro wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> > The Universal Declaration of Human Rights does not require that a
> > volunteer organisation grant membership to a rapist, even if said rapist
> > has not been found guilty in a court of law.
> Are you aserting that Jacob Appelbaum is guilty or are you talking about
> someone else? If you cannot prove something, it is a lie.
I am asserting that he's a rapist, an assertion that is backed up by an array of publicly available evidence.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Wed, 2 Sep 2020 01:05:43 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 07:00:03PM -0500, quiliro wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Tue, Sep 01, 2020 at 05:59:46PM -0500, quiliro wrote:
> >> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> > The Universal Declaration of Human Rights does not require that a
> >> > volunteer organisation grant membership to a rapist, even if said rapist
> >> > has not been found guilty in a court of law.
> >> Are you aserting that Jacob Appelbaum is guilty or are you talking about
> >> someone else? If you cannot prove something, it is a lie.
> >
> > I am asserting that he's a rapist, an assertion that is backed up by an
> > array of publicly available evidence.
>
> You are backing it up by gossip. Nobody in that website is presenting
> their proof. They cannot not be held to their word. It is impossible to
> verify if they say the truth or if they lie.
Reporting of first hand experiences is not gossip.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Wed, 2 Sep 2020 01:54:44 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Sep 01, 2020 at 07:40:50PM -0500, quiliro wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Tue, Sep 01, 2020 at 07:00:03PM -0500, quiliro wrote:
> >> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >>
> >> > On Tue, Sep 01, 2020 at 05:59:46PM -0500, quiliro wrote:
> >> >> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> >> > The Universal Declaration of Human Rights does not require that a
> >> >> > volunteer organisation grant membership to a rapist, even if said rapist
> >> >> > has not been found guilty in a court of law.
> >> >> Are you aserting that Jacob Appelbaum is guilty or are you talking about
> >> >> someone else? If you cannot prove something, it is a lie.
> >> >
> >> > I am asserting that he's a rapist, an assertion that is backed up by an
> >> > array of publicly available evidence.
> >>
> >> You are backing it up by gossip. Nobody in that website is presenting
> >> their proof. They cannot not be held to their word. It is impossible to
> >> verify if they say the truth or if they lie.
> >
> > Reporting of first hand experiences is not gossip.
>
> If you believe what others say, that is your problem. I'd rather have
> proof.
How are you defining "proof" here?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Sun, 6 Sep 2020 02:29:24 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Sat, Sep 05, 2020 at 06:53:57PM -0500, quiliro wrote:
> Something that is "backed up by an array of publicly available
> evidence." This you have said. But you have not shown. A web page is not
> first hand testimonies.
Yes it is.
> The author is the only first hand testimony if it is verifiable. First
> hand testimonies must not only be shown. Those testimonies must also
> demonstrate that someone was penetrated sexually.
They do.
> That defines rape. Also, if someone says something, that does not mean
> it is true. So proof is something much more complicated than what you
> are presenting and requires much more verification.
So, again, what do you mean by "proof"? What do you need to see here?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Sun, 6 Sep 2020 04:14:09 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Sat, Sep 05, 2020 at 09:24:50PM -0500, quiliro wrote:
> A "yes it is"/"no it isn't" discussion will get us nowhere. In the end,
> no facts are in those words, just opinions. Unless you support with
> other evidence, I will not be convinced and will regard them as false
> accusations. I will drop it from now with you because you will not
> contribute anything useful.
What other evidence do you need? Why is your default to assume that these people are lying?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Mon, 7 Sep 2020 20:24:47 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Sep 07, 2020 at 10:36:03AM -0500, quiliro wrote:
> There is no evidence of any rape. There are anonymous texts only that
> accuse him of it. Why asume Jake is lying, when he is the only one that
> is putting his name on it?
Written descriptions of events are literally evidence.
> The person should not prove per is innocent. The accuser does not need
> to be open. But must show evidence beyond doubt of guilt.
That's the standard held in a court of law. But falsely accusing someone of rape is also a crime, and you seem willing to assert that Jake's victims are guilty of that.
> If you do not want to hang around him because you think it is probable
> he is guilty, that is understandable. Another thing is dragging others
> to take suspicions as irrefutable truth. If that was somone's attitude
> against you, they would think you have a hidden agenda in favour of
> someone who has interests against Jake. But even if there are thinks
> that look spooky in your acts, no one has not made that accusation
> against you because the evidence is not enough.
Daniel has repeatedly suggested that organisations that chose to cut ties with Jake acted inappropriately. Is it reasonable to question Daniel's motivations?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: expulsions vs Reproducible Builds
Date: Tue, 8 Sep 2020 02:46:33 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Sep 07, 2020 at 05:47:14PM -0500, quiliro wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Mon, Sep 07, 2020 at 10:36:03AM -0500, quiliro wrote:
> >
> >> There is no evidence of any rape. There are anonymous texts only that
> >> accuse him of it. Why asume Jake is lying, when he is the only one that
> >> is putting his name on it?
> >
> > Written descriptions of events are literally evidence.
>
> They are evidence that someone knows how to write, not that someone did
> something depicted in that text.
It might not be sufficient evidence to convince you, but that doesn't mean it's not evidence.
> >> The person should not prove per is innocent. The accuser does not need
> >> to be open. But must show evidence beyond doubt of guilt.
> >
> > That's the standard held in a court of law. But falsely accusing someone
> > of rape is also a crime, and you seem willing to assert that Jake's
> > victims are guilty of that.
>
> I cannot accuse anyone because all of them are aliases. The only one
> that has done that openly is you. I am not interested in accusing you. I
> am just interested in rescueing the name of a person that has done
> good...at least from what I have seen personally. RMS, Assange,
> Appelbaum look like victims. I cannot prove it. But they deserve to be
> held innocent until proved guilty...in my book.
You said that you would treat them as false accusations. That's not merely deciding that Jake is innocent until proven guilty, that's saying that you believe a set of people are guilty of breaking the law. To be clear, it is absolutely your right to believe that Jake's accusers are breaking the law! But you can't simultaneously say that you believe Jake is innocent until proven guilty while also saying that those who accuse him are guilty despite not having been proven so.
> >> If you do not want to hang around him because you think it is probable
> >> he is guilty, that is understandable. Another thing is dragging others
> >> to take suspicions as irrefutable truth. If that was somone's attitude
> >> against you, they would think you have a hidden agenda in favour of
> >> someone who has interests against Jake. But even if there are thinks
> >> that look spooky in your acts, no one has not made that accusation
> >> against you because the evidence is not enough.
> >
> > Daniel has repeatedly suggested that organisations that chose to cut
> > ties with Jake acted inappropriately. Is it reasonable to question
> > Daniel's motivations?
>
> It is reasonable to have an opinion about it. His motivations are
> clear. He felt that FSFE was under bad leadership. He shows it.
What does that have to do with his repeated suggestions that it was inappropriate for Debian to cut ties with Jake?
> This thread has reached a point there is no more you have contributed to
> this discussion in the last few emails. There is enough evidence to
> conclude that you have no proof that a the crime was commited. I will
> not discuss any other thing about the topic unless there is credible
> evidence. I do not trust the direction you are taking this "yes it is /
> no it isn't" conversation. I feel your intentions are not clean and that
> you try to act against me. It looks as if you are trying trick me in
> several ways. I will not answer any more of your questions.
Despite asking you several times, you have failed to say what you would actually need to see in order to conclude that Jake is a rapist. What do you mean by "credible evidence"?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: NSA, GCHQ & Debian links, Jonathan Wiltshire, Tiger Computing?
Date: Tue, 27 Oct 2020 22:01:06 +0000
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Oct 27, 2020 at 08:56:06AM +0100, Daniel Pocock wrote:
>
>
> On 27/10/2020 05:15, Matthew Garrett wrote:
> > On Mon, Oct 26, 2020 at 10:30:57PM +0100, Debian Community News Team wrote:
> >> Garfield is going to love this... Tiger Computing could be the link from
> >> GCHQ to Debian
> >>
> >> https://debian.community/jonathan-wiltshire-debian-falsified-harassment-claims-tiger-computing-gchq/
> >
> > Could you walk us through this a little more clearly? Is the suggestion
> > that GCHQ infiltrated DAM and that your expulsion from Debian was
> > encouraged by individuals working for the British signal intelligence
> > organisation?
>
> Are you suggesting the individuals working for the British signal
> intelligence organisation are lazy and never thought of infiltrating
> Debian because they are busy doing crosswords?
If GCHQ wanted to infiltrate Debian then I have no doubt that they could do so. Are you asserting that they have done so?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Daniel Pocock censored at Techrights by its administrator
Date: Tue, 30 Mar 2021 09:52:23 +0000
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Sun, Mar 21, 2021 at 07:42:43PM +0100, Debian Community News Team wrote:
> If accusers are so certain that Jacob Appelbaum is a rapist, why do they
> spend so much time trying to censor web sites but in four years, not one
> accuser had time to visit a police station and file a report?
Does visiting a police station change whether or not something happened?
Subject: Re: Pentagon linked to RMS, Jacob Appelbaum plots through Debian
Date: Sun, 4 Apr 2021 02:13:54 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Sun, Apr 04, 2021 at 12:37:54AM +0200, Daniel Pocock wrote:
>
> Both RMS and Appelbaum cases... Pentagon, White House
Why do you keep defending a rapist?
Subject: Re: Pentagon linked to RMS, Jacob Appelbaum plots through Debian
Date: Mon, 5 Apr 2021 18:38:22 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Apr 05, 2021 at 10:54:02AM -0400, Robert Call (Bob) wrote:
> On Sun, 2021-04-04 at 02:13 +0100, Matthew Garrett wrote:
> > On Sun, Apr 04, 2021 at 12:37:54AM +0200, Daniel Pocock wrote:
> > > Both RMS and Appelbaum cases... Pentagon, White House
> >
> > Why do you keep defending a rapist?
> >
>
> Why do you continue to apply labels to people based on hearsay and the
> toxic mob? You nor anyone else has provided **any** compelling evidence
> that Appelbaum is a "rapist".
Multiple people provided first hand accounts of his actions towards them.
Subject: Re: Pentagon linked to RMS, Jacob Appelbaum plots through Debian
Date: Mon, 5 Apr 2021 22:05:12 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Apr 05, 2021 at 04:04:43PM -0400, Robert Call (Bob) wrote:
> Again, it's hearsay until you've provided corroborating evidence that
> would back up such claims. You can assert the claim is true all you
> want but the burden of proof is on YOU! If you can't provide such
> evidence, I suggest you stop with these toxic games of telephone.
Such as https://hypatia.ca/2016/06/07/he-said-they-said/, an incident in which a third party was present and supports the telling of events? Or https://medium.com/@eqe/not-working-for-us-bff58e96c2ea, which also involves a witness supporting the account of one of his victims? If not, what sort of corroborating evidence are you looking for?
But on a side-note - why pick this specific topic to leap to someone's defence? Daniel's been engaging in a long-term harassment campaign against multiple volunteer contributors to Debian based on, well, zero evidence at all. Are you as angry about that?
Subject: Re: Pentagon linked to RMS, Jacob Appelbaum plots through Debian
Date: Tue, 6 Apr 2021 12:12:40 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Tue, Apr 06, 2021 at 01:09:17PM +0200, Daniel Pocock wrote:
> Organizations need a process for evaluating incidents like this fairly
> and objectively.
What was your process for evaulating Jake's behaviour fairly and objectively? Why did you conclude that the accusations weren't sufficient for you to believe them?
Subject: Re: Elections
Date: Sat, 29 May 2021 03:30:33 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: quiliro@riseup.net
CC: discussion@lists.fsfellowship.eu
On Fri, May 28, 2021 at 08:54:57PM -0500, quiliro@riseup.net wrote:
> I mean that a community which was backing Richard Stallman and his quest
> of freedom is being programatically taken over by someone who opposes
> him and conflates his opinions with rape. Yes, I believe that is you.
> I believe that people who do really care about freedom would handle the
> issue in a different way and would not support this puppety move from
> corporations.
I don't believe that I've ever conflated his opinions with rape? It's possible that I've been careless with wording at some point, but while I may disagree with Stallman on multiple points I wouldn't categorise any of those as amounting to sex crimes. I will say that I've spent extensive amounts of time working with him to attempt to help him understand why some of his behaviour hurts free software rather than helping it, and was only willing to take this step because I saw no other viable approach.
I also disagree with the claim that I've "taken over" this community in any way. As I said, I believe that functional representation of this community requires at least three people, and I've asked Daniel to give me access to the blog in order to broadcast an appeal for people who'd be willing to assist in that. I'm not proposing to unilaterally appoint people, but in the absence of anyone else who was willing to stand for election we clearly need to find some way to identify potential candidates.
Subject: Re: Elections
Date: Fri, 4 Jun 2021 21:43:55 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: quiliro@riseup.net
CC: discussion@lists.fsfellowship.eu
On Fri, Jun 04, 2021 at 03:02:38PM -0500, quiliro@riseup.net wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> > Where did I perform this conflation?
>
> Sun, 4 Apr 2021 02:13:54 +0100 on this mailing list.
I was referring to Jake (hence "a rapist", meaning I was only talking about one of the people mentioned there). Sorry if I wasn't clear - I disagree with RMS on multiple topics, but I don't believe him to be a rapist or for his acts to be anywhere near as bad as Jake's.
Subject: Re: Elections
Date: Sat, 5 Jun 2021 04:23:15 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: quiliro@riseup.net
CC: discussion@lists.fsfellowship.eu
On Fri, Jun 04, 2021 at 09:15:20PM -0500, quiliro@riseup.net wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Fri, Jun 04, 2021 at 03:02:38PM -0500, quiliro@riseup.net wrote:
> >> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> > Where did I perform this conflation?
> >>
> >> Sun, 4 Apr 2021 02:13:54 +0100 on this mailing list.
> >
> > I was referring to Jake (hence "a rapist", meaning I was only talking
> > about one of the people mentioned there). Sorry if I wasn't clear - I
> > disagree with RMS on multiple topics, but I don't believe him to be a
> > rapist or for his acts to be anywhere near as bad as Jake's.
>
> I do not see either as bad. I am no one to judge them because I have no
> direct experience with any major problem with them. I can only retrieve
> testimonies which I cannot evaluate the truth or circumstances which
> have surrounded the alleged hurt caused. I only can see the direct
> benefit obtained by me from both of them: the free software movement and
> anonymity, respectively.
I can - Jake raped or sexually assaulted several people I know. No social benefit can be used to justify that.
Subject: Re: Elections
Date: Sun, 6 Jun 2021 03:38:24 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: quiliro@riseup.net
CC: discussion@lists.fsfellowship.eu
On Sat, Jun 05, 2021 at 08:36:27PM -0500, quiliro@riseup.net wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> > I can - Jake raped or sexually assaulted several people I know. No
> > social benefit can be used to justify that.
>
> I can't because I have no evidence. The evidence you present is not
> convincing to me.
If I've seen evidence that's convincing to me, what is the appropriate way for me to describe Jake?
Subject: Re: Elections
Date: Sun, 6 Jun 2021 19:07:25 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: quiliro@riseup.net
CC: discussion@lists.fsfellowship.eu
On Sun, Jun 06, 2021 at 12:18:46PM -0500, quiliro@riseup.net wrote:
> Matthew Garrett <mjg59@srcf.ucam.org> writes:
>
> > On Sat, Jun 05, 2021 at 08:36:27PM -0500, quiliro@riseup.net wrote:
> >> Matthew Garrett <mjg59@srcf.ucam.org> writes:
> >> > I can - Jake raped or sexually assaulted several people I know. No
> >> > social benefit can be used to justify that.
> >>
> >> I can't because I have no evidence. The evidence you present is not
> >> convincing to me.
> >
> > If I've seen evidence that's convincing to me, what is the appropriate
> > way for me to describe Jake?
>
> The way you do it is appropriate for you. How can I know what is
> appropriate for you? Perhaps you meant to ask something else.
So there's nothing wrong with me calling Jake a rapist if I've seen evidence that convinces me that he's a rapist?
Subject: Re: Elections
Date: Mon, 7 Jun 2021 07:16:16 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
Reply-To: discussion@lists.fsfellowship.eu
To: discussion@lists.fsfellowship.eu
On Mon, Jun 07, 2021 at 07:24:08AM +0200, Debian Community News Team wrote:
> If Garrett and his Debian buddies were in that group watching an alleged
> rape, why did they just watch it without trying to stop it?
I wasn't?
On Ted Walther, prostitute defamation, drugs & Debian
Subject: Re: Ted Walther's Expulsion
Resent-Date: Sat, 20 May 2006 05:53:26 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Sat, 20 May 2006 11:53:01 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Sat, May 20, 2006 at 12:59:02AM -0500, martin f krafft wrote:
> People have almost stopped talking about it. Let's not revive it.
> This is my preferred strategy.
"Everyone" believes that Ted was kicked out because he brought a prostitute to dinner. Given the uncertainty about how true this is[1], I think making it publically clear that Ted was expelled because of a long-running pattern of disruptive and anti-social behaviour would be worthwhile.
[1] Especially since it often seems to be accompanied by "Ted threatened to kill prostitutes on planet", which appears to be demonstrably untrue. Ted did enough bad things that we can argue in favour of his expulsion without having to resort to that.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Events at the DebConf Dinner
Resent-Date: Mon, 5 Jun 2006 09:36:32 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Mon, 05 Jun 2006 10:36:40 -0400
From: Micah Anderson <micah@debian.org>
To: debian-private@lists.debian.org
CC: debian-private@lists.debian.org
MJ Ray wrote:> I bring it up because there seemed a blind spot about other
> drugs which were probably present and maybe played some role
> in the described mess. I'd hate to see a formal dinner where
> they were banned, but it seems important that DDs are aware of
> them and any future stewards can handle their effects humanely.
I don't know how people got onto the topic of speculating what drugs
various people were using at the debconf formal dinner, but it seems
really obtuse and highly speculative for no particular purpose than just
to blahblah for the fun of it. I find such a discussion about things
that were "probably present and maybe played some role" to be incredible
wastes of bandwidth.
If people want to discuss the potential variables of drugs, drink, red
meat, sleep, caffeine, altitude, synesthesia induced by the mariachis,
air quality affect, water, etc. please do it at your local pub with
friends, where speculative gossip belongs, rather than spewing it all
over my inbox like Montezuma's revenge.
micah
Subject: Re: Java, drugs and rock&roll
Resent-Date: Fri, 16 Jun 2006 09:04:08 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Fri, 16 Jun 2006 15:03:56 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Fri, Jun 16, 2006 at 03:55:23PM +0200, Sven Luther wrote:
> I believe that such a behaviour has no place in debian, and is indeed of the
> kind of hatefull bashing of minorities and other such that is being discussed
> in these moments.
Discrimination against people who don't work well as part of a team is a perfectly reasonable thing to do. It's a minority that I'd rather didn't exist in Debian at all.
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Java, drugs and rock&roll
Resent-Date: Fri, 16 Jun 2006 09:48:25 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Fri, 16 Jun 2006 15:48:16 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Fri, Jun 16, 2006 at 04:10:50PM +0200, Bill Allombert wrote:
> I posit that people starting expulsion process are part of that
> category. If you prefer to get rid of people instead of working with
> them, you do no not work well as part of a team.
Are you suggesting that anyone who felt the project would be better off without Ted is unable to work well as part of a team?
It's an unfortunate fact that it is impossible to work with some people without making compromises that limit your own enjoyment of the activity. As an (extreme) example, the fact that my officemate is currently showing signs of extreme paranoia (to the extent of unplugging my computer and phone whenever I'm not in the office) makes it impossible to work with her. Is my willingness to start a formal complaints procedure against her a sign that I'm not a good team player?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Java, drugs and rock&roll
Resent-Date: Sat, 17 Jun 2006 07:06:06 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Sat, 17 Jun 2006 13:05:56 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Fri, Jun 16, 2006 at 05:06:45PM +0200, Bill Allombert wrote:
> On Fri, Jun 16, 2006 at 03:48:16PM +0100, Matthew Garrett wrote:
> > Are you suggesting that anyone who felt the project would be better off
> > without Ted is unable to work well as part of a team?
>
> There have been no expulsion process started against Jonathan, and the
> DAM still have not published their rationale for removing him, so
> no, I was not suggesting that.
Ok, let me rephrase the question. If I had started an expulsion process against Ted, would you have accused me of being unable to work well as part of a team?
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Release management and discussion
Resent-Date: Tue, 29 Aug 2006 02:53:48 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Tue, 29 Aug 2006 08:53:43 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Tue, Aug 29, 2006 at 12:03:30AM -0500, Manoj Srivastava wrote:
> I must be doing something right. My concerns about the
> relationships and other intangibles (like reactions of payment to
> some members making an effort [the scientific American recently had
> the results of only rewarding one monkey with bananas when two were
> required to pull them within reach]) have now been framed first as
> childish temper tantrums, and now by the DPL as "religious" arguments,
> neatly sidestepping actually facing the concerns I raised.
Dude, he was calling /me/ childish. I really don't think you can argue with him on that point.
(No, I've no idea why I'm still here either. I'm sure I'll stop getting these soon :) )
--
Matthew Garrett | mjg59@srcf.ucam.org
Subject: Re: Release management
Resent-Date: Mon, 28 Aug 2006 11:34:30 -0500 (CDT)
Resent-From: debian-private@lists.debian.org
Date: Mon, 28 Aug 2006 17:34:20 +0100
From: Matthew Garrett <mjg59@srcf.ucam.org>
To: debian-private@lists.debian.org
On Mon, Aug 28, 2006 at 06:18:48PM +0200, Josselin Mouette wrote:
> This is not about paying people. This is about paying the developers
> themselves. About splitting the developer base in two. About conflicts
> of interests.
Now that my resignation is pending, I'll just take the opportunity to say something I've wanted to for a long time:
Fuck you Joss. Fuck you vigorously with a chainsaw. Your continual whining and conspiracy theories have done more to encourage me to stab people to death than anyone else in recent history. I hope you have a miserable life that lasts longer than you want it to. And I mean that in the most sincere and honest manner possible. Should we ever come into contact socially, please do not attempt to initiate communication with me.
Love,
--
Matthew Garrett | mjg59@srcf.ucam.org
If you have a real concern about abuse, don't waste time behaving like a sock puppet, go to the police
Pope Benedict died on 31 December 2022.
Cardinal George Pell appeared in news reports a few days later. They revealed
he had been living in Rome after his acquittal and release from a prison in
Australia.
One of the news reports directed me to the unredacted version of the dossier
about the Archdiocese of Melbourne. It was fascinating reading through the
minutes of the church's internal committees side-by-side with the evidence
from debian-private (leaked) whisper network.
On 10 January 2023, I decided to drive across the Great St Bernard Pass to Italy
and file a complaint with the Carabinieri.
The late Cardinal Pell died by the time I arrived back home that night.
If Garrett really knows something about abuse, why does he waste so much time
on free software mailing lists acting like a sock puppet?
Incidentally, the Cardinals wear a Red Hat, a lot like Garrett's former
employer,
IBM Red Hat. The UDRP panel found that
I am a victim of harassment and abuse by Garrett's former employer.
Police receipt and Great St Bernard tunnel receipt:

Please see the
chronological history of how the Debian harassment and abuse culture evolved.
































 Freedom (The Open Frontier)
Freedom (The Open Frontier) Friends (Our Fedora Story)
Friends (Our Fedora Story) Features (Engineering Core)
Features (Engineering Core) First (Blueprint for the Future)
First (Blueprint for the Future) Submit to the Flock 2026 CFP
Submit to the Flock 2026 CFP
















comments? additions? reactions?
As always, comment on mastodon: https://fosstodon.org/@nirik/115951447954013009