It seems odd to me that
Ireland has a public holiday for St Patrick's Day but
England doesn't have an equivalent public holiday for
St George's Day.
The Universal Declaration of Human Rights tells us everybody
is equal. Therefore, we have a right to equal holidays. I don't
feel there is anything unreasonably nationalistic about this. The
people of every country and culture like to reflect on their heritage
for a day. Whether you are a lefty or a conservative, I feel you have
a right to celebrate your national day and your national Saint as
you see fit.
In my earlier
blog about youth crime and social media, I proposed we need more
Saints like Carlo Acutis. The question of who qualifies to be
a Saint is a question for each religious institution. Nonetheless,
many countries also give great political significance to their Saints.
For example, the decision to have a public holiday for St Patrick or
St George is not a decision for the Pope or the Archbishop of
Canterbury. Likewise, deciding to name parks, roads, lakes and entire
villages in honour of a Saint is not a religious decision. Those
decisions are made by the state.
If new Saints are created by any religious institution then I'm
entirely in favour of naming holidays and places in their honour.
Whenever anybody mentions the subject of
cult behaviour in a group, it is not long before people start
avoiding the subject by speculating about the mental health of
the person who was sane enough to ask the question in the first place.
We see much the same problem in
cybersecurity. When professionals who work in this field every
day dare to tell our friends they can't trust
Google, it isn't long before somebody speculates that we are
being paranoid party poopers.
One of the reasons I made a submission to the cult inquiry in
the first place is because of the similarities between cult tactics and
social engineering attacks in the free software community. A
specific example is the
Code of Conduct (CoC) gaslighting.
The chair of the committee,
Ella George, has issued a second apology which deserves some
analysis. I am printing it here in full and my analysis appears
below.
Subject: Important update regarding privacy incident on 29 July 2026
Date: Thu, 30 Jul 2026 09:54:42 +0000
From: COFG <COFG@parliament.vic.gov.au>
To: COFG <COFG@parliament.vic.gov.au>
Good evening,
I am writing to provide a further update regarding the unacceptable privacy incident which occurred yesterday where email addresses of inquiry stakeholders were made public. On behalf of the Committee, I offer my sincerest apology that this has happened, and for any distress it has caused.
This occurred due to an administrative error in the Committee Secretariat’s processes.
I want to assure you that this matter is being taken very seriously. Throughout this inquiry, the safety and wellbeing of all participants has been an important consideration of its processes. The Committee deeply regrets that this incident may have impacted your trust in the process.
I have raised this with the Clerk of the Legislative Assembly, and the Clerk’s Office is conducting a full review into the Committee Secretariat’s processes to ensure this does not happen again.
Please note that the stakeholder list is connected with a committee proceeding. Therefore, further disclosing, using or sharing that information, including email addresses, could be a breach of parliamentary privilege.
I kindly ask that, if you have not already done so, you please delete the email from your inbox (including in any related folders or Sent Items), and refrain from forwarding or sharing its contents.
I appreciate the cooperation shown by stakeholders and ask for your continued cooperation while the matter is reviewed.
The Office of the Victorian Information Commissioner (OVIC) provides information and guidance to individuals in relation to what actions you can take to reduce the risk of harm as a result of a privacy breach involving email addresses. These actions include:
* contacting *Victoria Police* on 13 14 44 if you are concerned about
your physical safety. If you have *immediate safety concerns, call 000*;
* if you experience online bullying or harassment, visit the Office of
the eSafety Commissioner at esafety.gov.au
. For more tips about staying safe
online, visit Stay Smart Online at www.staysmartonline.gov.au; and
* to assist with any mental or emotional distress, contact your
General Practitioner, Beyond Blue on 1300 22 4636 or Lifeline on 13
11 14.
Please refer to additional information available on OVIC’s website: https://ovic.vic.gov.au/privacy/for-the-public/data-breaches-and-you/.
The Committee has arranged a free dedicated counselling support service with the Parliament’s employee assistance provider, Converge. Any stakeholder requiring support may contact Converge using the below information.
*Service:*24/7 dedicated counselling support.
*Available:*6:00pm Thursday 30 July 2026 to 11:59pm Sunday 9 August 2026 – 24/7
*To access the service, please call 1300 687 327*
1. You will be prompted by the *IVR to select 1 *for Critical Incident
support.
2. Once your call goes through, explain that you are calling to access
standby phone support with reference number [ redacted ]
3. The call will be transferred straight through to a consultant who is
on standby.
4. If a consultant is unavailable, they will obtain your full name and
contact number, which will be passed on to the consultant to reach
out to you directly
Additional support services have also been listed below.
The Committee’s inquiry was informed by a wide range of views and experiences, and we remain grateful for the contribution of our stakeholders and the trust they placed in the Committee. Deeply thoughtful and considered evidence shaped the Committee’s report, its 98 findings and 39 recommendations. Many people shared their experiences for the first time, and demonstrated immense courage in speaking out.
Our report charts a pathway for the Victorian Government to better support people who have been part of coercive high-control groups, and better protect Victorians from harm.
Kind regards,
Ella George
Please be aware that the following support services are also available:
* *Blue Knot Helpline and Redress Support Service* – If you or someone
you care about is living with the effects of abuse, neglect,
violence or exploitation – Call 1300 657 380
available 9 am to 5 pm 7 days a week, or visit http://blueknot.org.au/.
* *Kids Helpline* – Call 1800 55 1800
available 24/7, or visit https://kidshelpline.com.au/.
* *Sexual Assault Crisis Line* – Call 1800 806 292
or contact your local sexual assault service
https://peak.sasvic.org.au/servicemap#gsc.tab=0.
* *Sexual Offences and Child Abuse Investigation Team (SOCIT)* – visit
Find contact details for each SOCIT across the state
https://www.police.vic.gov.au/sexual-offence-child-abuse-teams-centres.
* *Victims of Crime Helpline* – Call 1800 819 817,
available 8 am to 7 pm Monday to Friday and
8 am to 5 pm Saturday, Sunday and public holidays, or Text 0427 767
891, or visit victimsofcrime.vic.gov.au
https://www.victimsofcrime.vic.gov.au/.
* *13YARN* – Call 13 92 76, to talk with an
Aboriginal or Torres Strait Islander Crisis Supporter, or contact
enquiries@13yarn.org.au
One person sent this response to my email:
This is an important report that the Committee has released, don’t get in the way of it
In fact, without the scandal, many people probably wouldn't have
noticed the release of the report. Thanks to the scandal, I suspect ten
times more people are downloading the report of the cult inquiry if
for no other reason than checking if any groups they belong to have been
included.
As mentioned in another one of my own reports, on the day the late
Cardinal George Pell died, I was in Italy to talk about coercive
control problems with the Carabinieri.
After extensive review and discussion on the ticket request and in recent council meetings (see meetbot for 29 July and 15 July 2026), the Fedora Council would like to initiate the policy change policy process for ratifying the Fedora Forge Usage policy. This document is open to public feedback (if any) for a minimum of two weeks. If there are no significant changes to be made to the policy based on community feedback after Thursday, 13 August 2026, this policy will go to a formal ticket vote for Council to approve or reject. If there are significant changes to be made to the document, Council will review the policy and, if necessary, extend the feedback period before calling for an official vote. Please provide feedback on the discussion post.
Thank you everyone for your contributions to this policy so far, and on behalf of the Council, we look forward to working with you all to ratify this policy soon.
Fedora Forge Usage Policy
Welcome to the Fedora Forge. This Forgejo instance is provided by the Fedora Infrastructure team to support the daily operations, development, and collaboration of the Fedora Project.
To ensure this service remains reliable, secure, and useful for everyone in the Fedora community, all users must adhere to the following usage policy.
1. Scope, Criteria, and Exceptions
The Fedora Forge is a dedicated workspace for the Fedora Project. Historically, the Fedora Project utilized pagure.io, which operated as a general-use public forge where Fedora repositories coexisted alongside personal projects, unrelated upstream software, and individual portfolios.
The Fedora Forge (powered by Forgejo) intentionally adopts a narrower scope. It is not a public, general-use Git hosting provider. It is an internal piece of project infrastructure, explicitly provisioned to host the code, documentation, and tooling that directly build, manage, and govern the Fedora Project.
Criteria for “Fedora Project Related”
To qualify for hosting on the Fedora Forge, a repository must meet at least one of the following criteria:
Infrastructure and Operations: Configuration management, deployment scripts, or tooling used by the Fedora Infrastructure team to run the project.
Release Engineering and Packaging: Tools, scripts, and templates used to build, compose, and distribute Fedora releases, editions, and spins.
Governance and Team Organization: Trackers, documentation, and collaborative spaces for official Fedora Teams, Special Interest Groups (SIGs), Working Groups, and Fedora Council initiatives.
Fedora-Specific Software: Software projects conceptualized and developed primarily to serve the Fedora community (e.g., Fedora Badges, Bodhi, fedmsg).
Exceptions and Special Cases (Ecosystem Upstreams)
While general upstream development should happen on public forges (like GitHub, GitLab, or Codeberg), the Fedora Project recognizes that certain large-scale upstream projects are so deeply intertwined with Fedora’s infrastructure and history that they qualify as exceptions.
Recognized Exceptions:
Foundational infrastructure tools heavily maintained by Fedora and Red Hat ecosystem contributors (e.g., Koji, FreeIPA).
Core system components where the primary development team is historically rooted in the Fedora community and relies on Fedora Infrastructure for their workflow.
Note: Being packaged in the Fedora repository does not automatically grant a project exception status to use the Fedora Forge as its upstream host.
Decision Process for Edge Cases
If a community member is unsure whether their project fits the scope or qualifies as an ecosystem exception, the following process applies:
Request Submission: The requester must open a ticket on the Fedora Infrastructure tracker, detailing the project’s purpose, its connection to Fedora, and why it should be hosted on the Fedora Forge rather than a public alternative.
Infrastructure Review: The Fedora Infrastructure team will conduct an initial review against the established criteria to assess technical feasibility and resource impact.
Steering Committee Consultation: If the request falls into a gray area, the Infrastructure team will escalate the ticket to the Fedora Engineering Steering Committee (FESCo) or the Fedora Council for a policy ruling.
Final Resolution: The decision will be documented in the ticket. If denied, the requester will be encouraged to host the project on a public forge and mirror specific components if strictly required for internal Fedora builds.
2. Access and Authentication
Access to the Fedora Forge is integrated with our central identity systems to ensure secure and accountable access.
Account Creation and Login: All authentication is handled via the Fedora Account System (FAS). You cannot create a local account directly on the Forgejo instance. To log in, use the Single Sign-On (SSO) integration with your active FAS credentials.
Personal Namespaces: Upon your first login, a personal namespace (e.g., forge.fedoraproject.org/your-fas-username) is automatically provisioned for you. You can only fork repositories into this space, creation of new repositories is allowed only under Organization.
Organizations and Teams: To prevent organizational sprawl, the creation of top-level Organizations (e.g., /infra or /quality) is restricted. If your Fedora team or SIG needs a dedicated Organization space, please open a ticket with the Forge team. Organization owners are responsible for managing team access within their assigned space.
Account Deactivation: If your FAS account is suspended, disabled, or marked as inactive, your access to the Fedora Forge will be automatically revoked. Repositories hosted in your personal namespace may be archived or removed if your account remains inactive for an extended period. If you are leaving the project, please transfer ownership of any critical tools to a Fedora Organization or an active co-maintainer before your departure.
3. Code of Conduct and Community Behavior
The Fedora Forge is a collaborative space. All activity on this platform is strictly governed by the Fedora Code of Conduct.
4. Prohibited Activities
To ensure the Fedora Forge remains performant, secure, and legally compliant, the following activities and content are strictly prohibited:
Non-Fedora Projects: As stated in the scope, this Forge is not a general-purpose Git host. Personal portfolios, dotfiles, or hobby projects not directly tied to Fedora are prohibited.
Malicious Content: Hosting malware, exploits, botnet command-and-control infrastructure, or phishing materials. (Note: Security-related tools strictly used for Fedora infrastructure testing must be explicitly approved).
Proprietary and Copyrighted Material: Uploading copyrighted materials you do not have the right to distribute, or hosting proprietary, closed-source binary blobs. All code should be open source and compliant with Fedora’s licensing guidelines.
Exposing Secrets: Committing sensitive information such as passwords, API tokens, private SSH keys, or Personally Identifiable Information (PII).
System Abuse: Engaging in activities that degrade the performance of the Forgejo instance or its runners, such as aggressive network scraping, DDoS attacks, or intentionally triggering infinite CI loops.
Cryptocurrency Mining: Using the Forge or its CI/CD runners to mine cryptocurrency is strictly forbidden and will result in an immediate, permanent ban.
5. Resource Limits and CI/CD
We want to empower Fedora teams with the tools they need, but we must also manage our infrastructure costs and storage effectively.
Repository Size: Git is not a backup system. Please keep repositories focused on source code and text-based documentation.
Repositories should ideally remain under 500MB.
If your project requires large assets (e.g., design files, test datasets), you must use Git LFS (Large File Storage).
Forgejo Actions and CI Runners:
Shared Infrastructure: The default CI runners provided by Fedora Infrastructure are a shared community resource. Jobs should be optimized to run efficiently and are subject to a maximum timeout of 10 minutes per job.
Community-Owned Runners (Bring Your Own): We highly encourage larger teams, SIGs, and Working Groups with extensive testing or specific architectural requirements (e.g., heavily utilizing ARM, RISCV, or requiring long build times) to provision and register their own runners. Dedicated runners can be attached directly to your Organization or specific repositories.
Compliance for Custom Runners: Even if your team provides the compute resources, any runner connected to the Fedora Forge is an extension of our infrastructure. All workflows and actions executed on community-owned runners must strictly comply with Section 4 (Prohibited Activities). You may not use custom runners to bypass policy (e.g., no cryptocurrency mining, no building unrelated non-Fedora upstream projects, and no malicious network scraping).
Registration Process: To register a dedicated runner for your team, please review our Runner Registration Docs and ensure your runner is secured according to Fedora Infrastructure standards.
API Usage: Automated scripts and bots interacting with the Forgejo API must respect rate limits and include descriptive user-agent strings identifying the tool and its maintainer.
6. Repository Lifecycle and Organization
Naming Conventions: We have a general naming convention, there should be tickets repository in your Organisation to have a single point of opening tickets relevant to your group. The docs repo in you organization should point to your groups official sources for docs.fedoraproject.org namespace. In other cases please use clear, descriptive names for repositories so other community members can easily understand their purpose.
Archiving: Projects that are no longer actively maintained should be archived (marked as read-only) to signal their status to the community. Active Forge organization owners should archive repos as necessary. If needed (e.g., in the case of an inactive organization), the Infrastructure team reserves the right to archive repositories that have seen no activity after trying to contact the organization owners.**.
Deletion: If you need an Organization or repository completely deleted, please open a ticket with the Forge team. The Infrastructure team also reserves the right to delete abandoned, non-compliant, or empty repositories to maintain a clean workspace.
7. Support and Abuse Reporting
Getting Help: For technical issues with the Fedora Forge (e.g., CI runner failures, login issues, requesting an Organization), please open a ticket on the Forge team tracker or ask in the #fedora-admin Matrix channel.
Reporting Code of Conduct Violations: To report a CoC violation occurring on the Forge, please contact the Fedora Code of Conduct Committee.
Reporting Security/Legal Issues: To report a security vulnerability on the platform, exposed secrets, or a DMCA/copyright violation, please immediately send an email to Fedora Infrastructure team.
The parliament launched the inquiry into Cults and Organized Fringe groups (COFG)
in 2025. Victims and witnesses were invited to make both formal submissions
and anonymous reports through the parliament's web site. Participants were
told our contact details would be private, even if details from our testimonies
were included in the public report.
Your contact details, including your address, email and phone number, will not be published. We ask these questions for verification purposes only.
Nonetheless, when the committee published their report today they
accidentally used the CC function rather than BCC to send the report
to all the cult victims and witnesses. Therefore, we all received
names and contact details for other victims/witnesses.
About ten years ago, the 56 Dean Street HIV clinic in London made a
similar error. The group CC leaked the names and contact details of
numerous patients with HIV positive status. They were ordered to
pay a fine of £180,000 and they may have been subject to civil
litigation too.
Subject: RE: LA LSIC | Inquiry into the recruitment methods and impacts of cults and organised fringe groups – final report published
Date: Wed, 29 Jul 2026 03:31:53 +0000
From: COFG <COFG@parliament.vic.gov.au>
To: COFG <COFG@parliament.vic.gov.au>
Good afternoon,
We would like to sincerely apologise for the email sent earlier today
in which recipient email addresses were inadvertently included in
the CC field.
Due to an administrative technical error during the distribution process,
the email was sent with visible recipient details. We understand the
importance of protecting personal information and regret this mistake.
To help minimise any further disclosure of information, we kindly ask
that you delete the email from your inbox and any related folders
(including Sent Items if applicable), and refrain from forwarding or
sharing its contents.
We appreciate your understanding and cooperation. We are reviewing our
processes to help prevent a similar incident from occurring in the future.
If you have any questions or concerns, please contact us directly at
cofg@parliament.vic.gov.au .
Kind regards,
Legal and Social Issues Committee
Secretariat
Legislative Assembly
Parliament of Victoria
+61 3 8682 2628
parliament.vic.gov.au
This immediately prompted communication between people who have
been exposed.
Subject: COFG Cults inquiry: your invitation, did you feel passed over?
Date: Wed, 29 Jul 2026
From: Daniel Pocock <daniel@pocock.pro>
To: [ redacted ]
Were you invited to speak to the committee or did you feel you were
passed over?
After my earlier thank-you message to the committee, some people
indicated you felt left out. If you have $30,000, you can buy
preselection in a political party, get into parliament and publish
anything under parliamentary privilege. For everybody else, an
alternative report will be published on IPFS,
a technical solution that is equivalent to parliamentary privilege.
Catalonia used IPFS to publish information during their independence
campaign.
Did the report address your concerns or did they make no mention of
you?
Do you have leaks or other material that you would like to publish
anonymously but you can't do so in Australia?
Were you impressed by JuristGate, my takedown of the
judicial Establishment in Switzerland? What about the Cult of
Prince Alfred and the 1514
year old princess petition that cursed the Commonwealth Games?
25 July 2013, somebody leaked my resignation from the ALP to Crikey.
It compared the Catholic
abuse scandal to the politicians who abuse
refugees so they can make themselves look bigger.
My
COFG submission (censored) included evidence about the
proximity of Ben Carroll, churches, states and abuse. Some snippets
about Ben Carroll's proximity are published at the bottom of my
report about Jeremy Bicha (incest, pastor cover-up) and the death
of Adrian von Bidder on our wedding day (linked to EVP / Swiss
Protestant Party). Over $US120,000 has been spent to try and censor
those reports. An unknown amount of money has been spent to try and shut down
Techrights, an independent British web site that publishes
similar evidence about the incidence of abuse and [choose your
definition of the Establishment].
Look at the irony. Jacinta Allan and Jess Wilson are both brought
up in political families. They are products of the system, like
children of cults. The way they chewed up Jacinta and spat her out
again smells like a human sacrifice. Brittany Higgins too. Check
the true meaning of the word Scapegoat (from Wikipedia):
"A scapegoat is one of a pair of goats used in the Yom
Kippur Temple service during the era of the Temple in
Jerusalem. The scapegoat had a band of red wool placed on it,
and was then released into the wilderness, taking with it all
the sins and impurities of the people as an act of symbolic
atonement. The other goat was sacrificed."
It is creepy. First they lynched Will Fowles. Dan Andrews was
Premier but he was exercising powers reserved for a judge, making
declarations about guilt and innocence. On top of
that, Dan has a history with those he has judged (proof, with
photos, in my reports on the subject). In other words, by
pretending he is God, ignoring conflict of interest, bypassing the
judges and exercising such enormous humiliation over another man,
Dan Andrews turned the parliamentary Labour party into something
like a cult. Then they used Jacinta's dismissal at the last
minute before an election to bury the bigger legacy of Dan
Andrews. In the ancient tradition of the Scapegoat ritual so
described, which goat is which? Jacinta's male successor will
have a 3 month honeymoon period to blame any newly disclosed
scandals on the goat they used for this filler period between
Andrews' exit and Carroll's ascent.
Cults come in many shapes and sizes. You have a right to talk
about it. Sharing your experience can help other people too.
Thank you for anything you already contributed, whether it was
published or not.
If you want to send me anything or participate in a community-led
report or video then please don't hesitate to get in touch. More
videos are coming too.
We’ve just rolled out a new feature on Planet GNOME to bring our community discussions together! You can now opt in to automatically create a topic on discourse.gnome.org whenever you publish a new blog post.
Having comments centralized on Discourse makes it much easier for readers to discuss your posts, while also ensuring that all interactions are moderated under the GNOME Code of Conduct for a safer, healthier space. It is also a great way to give your content a bit more visibility with the active Discourse community without any extra manual work.
This is especially handy if you run a statically generated blog without an existing comment section, giving your readers a dedicated space to share feedback.
This feature is completely opt-in, so nothing will change for your feed unless you choose to turn it on. To get started, simply send a merge-request to Planet GNOME adding discourse_comments=1 to your blog entry in our config.ini file.
Since this is brand new, there might still be a few rough edges. If anything breaks or acts weird when you try it out, let us know and we’ll get it fixed as soon as we can.
The
UK may well have the strongest, most talented and most unique
tech sector in all of Europe.
Nonetheless, the majority of the
UK voters appear to be under the sway of corporations like
Google,
Facebook and
X/Twitter who are all run from the west coast of the
USA.
The reason for the problem is simple to understand: those very
same companies have divided the
UK into silos. Tech workers themselves make a post on
social control media
or they publish a video on
Youtube and the web site tells them thousands of people saw it.
In fact, what this means is thousands of people scrolled past it.
Some of those people may have read it.
In student union elections back in the 1990s, it was common practice
for students from one university to go and visit other universities
and spend time assisting an allied group in the other campus by
having fake discussions with their rivals. This was called "stooging".
For example, a stooge from the far left in the Melbourne University
Student Union would go to Monash University for a day and pretend to
be interested in the far-right candidates. The far-right candidates
would lose hours talking to these fake students who were never going
to vote for them anyway.
Social control media is a similar waste of time, like a virtual
version of stooging.
The alternative to
social control media is for people to go and speak to any contacts
they have in the region on a one-to-one basis, to meet like-minded groups
in the region or attend events in the region and start discussions
with people.
Even for those who don't vote in the district, engaging in
a face-to-face campaign is a vital way to learn and practice
campaign skills that will be useful in future elections.
The alternative is quite scary: the UK tech sector runs the
risk of waking up one day and finding out the people in charge
have signed away our ability to do basic things like modifying
apps on our phones or installing Linux on a new computer. As
the saying goes, the price of freedom is eternal vigilence. In
this case, the price of freedom is local campaigning in every
by-election.
While other candidates in the
Clacton-on-sea by-election rush to create manifestos, my ideas
on various topics are already well documented in previous posts on
my blog. I'm ready to begin the process of implementing them immediately
if the people of
Clacton-on-sea want me to do so.
One of those policy themes is the availability of rival app stores
for smartphones. The US president
Donald Trump and other leaders in his administration have frequently
told their allies to get serious about defence. Allowing a bunch of
immature men in California to control or restrict what citizens in other
countries put in our phones is a huge loss of sovereignty.
A Caesar cipher is a letter for letter exchange from a clear text to a encrypted text by shifting a set distance in the alphabet. Thus, if your set distance is 2, the letter A becomes C, the letter X becomes Z. To encrypt the last letters of the alphabet, you wrap around to the beginning, so Y becomes A and Z becomes B.
Caesar is commonly respelled to Ceasar, which I have done for this article. Use the spelling of your choice.
This is a fairly easy algorithm to code, and makes for a decent early class in python. Here are the steps I would go through to teach someone:
I would do this on Linux, of course, using vim, but that is my problem. I won’t go into editor usage.
Start by writing and executing a hello_world program:
vim ceasar.py:
#!/bin/python3
print("OK")
Make the file executable.
chmod +x ceasar.py
Run the program.
./ceasar.py
OK
Always work from success. Don’t try to do more until you can get this far. Make sure you understand what you have done.
The Line !/bin/python3 tells the you that this a script to be executed by the python interpreter. The #! will be read by the Linux Kernel when you execute the program. There are lots of magic numbers for different file types. This one tells Linux to treat the file as text, to start reading until a newline, and to execute the program named by that string, with the rest of the file contents fed into that interpreter. This is pretty complex stuff, and expect people to either zone out or ask lots of questions. You could, if necessary show a different scripting language, such as bash or ruby.
The print(“OK”) is a function. That function is responsible for the OK you see on the screen after running the program.
Once you get this far, you might want to have the students change the text from OK to Hello or something, so they can see how they affect change, and get feedback from coding.
Yeah, git. This will allow them to reset themselves later. Answering questions about this will probably kill the rest of the class session. But using git is fundamental to not losing your mind as a developer.
Next we are going to give them an input text. For this example, I will use the opening line from Pride and Prejudice:
“is, “It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.”
Jane Austen from PRide and PRejudice
The code should now look like this:
!/bin/python3
plain_text=”It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.”
print(plain_text)
This introduces the concept of variables. plain_text is a variable that uses the snake_case naming convention. The underscore allows you to separate words while telling python that the whole collection of characters is one variable name.
Run it.
./ceasar.py
It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.
Add to git and commit:
git add ceasar.py
git commit -m "plain text"
Now lets uppercase the whole thing.
The code will look like this:
#!/bin/python3
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
print(plain_text.upper())
And the difference from the previous code can be shown with git diff
git diff
diff --git a/ceasar.py b/ceasar.py
index 76c6294..388e25f 100755
--- a/ceasar.py
+++ b/ceasar.py
@@ -3,4 +3,4 @@
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
-print(plain_text)
+print(plain_text.upper())
The output looks like this:
$ ./ceasar.py
IT IS A TRUTH UNIVERSALLY ACKNOWLEDGED, THAT A SINGLE MAN IN POSSESSION OF A GOOD FORTUNE, MUST BE IN WANT OF A WIFE.
Add to git and commit:
git add ceasar.py
git commit -m "to upper"
We are trying to establish the good habit of capturing your successes.
Lets go through the plain text letter by letter, now.
#!/bin/python3
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
encrypted_text = ""
for letter in plain_text.upper():
encrypted_text += letter
print(encrypted_text)
Which will look like this when executed:
/ceasar.py
IT IS A TRUTH UNIVERSALLY ACKNOWLEDGED, THAT A SINGLE MAN IN POSSESSION OF A GOOD FORTUNE, MUST BE IN WANT OF A WIFE.
i.e. exactly the same as before. We might have fooled ourselves. But the next change is going to be an important step in the understanding of coding Lets do a change that shows we actually made things work. Commit to git before continuing.
Lets strip out all characters that are not A-Z.
git add ceasar.py
git commit -m "letter by letter"
Now we will strip out all non-Alphabet characters. Make the following change. The - at the start of the line means match and remove that line, replacing it with the lines below it that start with +. Do not include the + or - characters that are at the start of the line.
- encrypted_text += letter
+ if (letter >= 'A' and letter <= 'Z'):
+ encrypted_text += letter
Now your code should look like this:
#!/bin/python3
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
encrypted_text = ""
for letter in plain_text.upper():
if (letter >= 'A' and letter <= 'Z'):
encrypted_text += letter
print(encrypted_text)
Note that now we need to mentally put the spaces back in to read it. This is a shortcoming of the Ceasar cipher, and it is something we can address with more complex cpihers in the future.
Add to git in a similar manner to how I wrote earlier.
Note how the only thing that differs on each of these commits is the message. At this point, we should have a few. We can see them (from newest to oldest) using git log:
git log
commit 422eed0a5e0c5a0b30855a3a84ae7c77fbe3945b (HEAD -> main)
Author: Adam Young <adam@younglogic.com>
Date: Mon Jul 27 15:15:52 2026 -0400
letters only
commit af884dcb08921deddfca70bcde548762310c3dc0
Author: Adam Young <adam@younglogic.com>
Date: Mon Jul 27 15:05:14 2026 -0400
letter by letter
commit 6156eaeafcaf7054044aca41aebf8f8bfe456172
Author: Adam Young <adam@younglogic.com>
Date: Mon Jul 27 14:57:21 2026 -0400
to upper
commit d739450b2c89f7e566d36f5ff201d2807bd72346
Author: Adam Young <adam@younglogic.com>
Date: Mon Jul 27 14:54:16 2026 -0400
plain text
commit 58477d16f983d2d2a32c6e4ba9769313d774b644
Author: Adam Young <adam@younglogic.com>
Date: Mon Jul 27 14:49:01 2026 -0400
hello world
Now we will convert from the letters A to Z to their numerical equivalent. We are using an encoding scheme called ASCII (American Standard Code for Information Interchange) that maps 'A' to the number 65. The rest of the alphabet follows in standard order: B=66, C=67 and so on. So to convert, we use the ord function (short for ordinal).
To convert 'A' to 65, we would write
val = ord('A')
Lets do only that and see what we get. Yeah, this is going to corrupt our output, but it will be illuminating. After the line
encrypted_text += letter
add these lines
val = ord(letter)
print(f"ordinal = {val}")
This will print out a lot of output, so much that it will scroll off the screen. The last few lines look like this:
We won't commit this to git, as it is a broken stage. Lets instead do some arithmatic.
In order to perform the portion of the Ceasar cipher that wraps around, we want to use the arithmetic operation of modulus. This is the remainder function of division. Since there are 26 letters, the number 0 through 25 are returned unchanged, but any number larger than 25 will instead return a number 0-25. In python, this is the % operator. You might want to show this in a stand alone fashion.
Note that I am going to run the python interpreter from the command line to show this.
$ python3
Python 3.14.4 (main, Jun 18 2026, 14:25:02) [GCC 15.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> ord('A')
65
>>> 25 % 26
25
>>> 27 % 26
1
>>> ord('A') % 26
13
However, we don't want to convert 'A' to 13. So, we are going to convert 'A" from 65 to 0, B to 1, and so on. We do this by subtracting the ord value of 'A' from each letter:
>>> ord('A') % 26
13
>>> ord ('A') - ord('A')
0
>>> ord ('B') - ord('A')
1
>>> ord ('C') - ord('A')
2
>>> ord ('Z') - ord('A')
Now we can perform cipher change. For example, if we wanted to encrypt Z by 13:
>>> (ord ('Z') - ord('A') + 13) % 26
12
To convert this back to a character, add the ord value of 'A" and use the chr function.
>>> chr(12 + ord ('A'))
'M'
To exit the interpreter, run the quit function like this
quit()
Lets add this logic to our code. IT should look like this.
#!/bin/python3
#!/bin/python3
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
encrypted_text = ""
key = 13
for letter in plain_text.upper():
if (letter >= 'A' and letter <= 'Z'):
plain_val = ord(letter) - ord('A')
encrypted_val = (plain_val + key) % 26
encrypted_text += chr(encrypted_val + ord('A'))
print(encrypted_text)
~
Note that the function is chr, and not char. char is a key word in python, and the error message might be a bit hard to debug if you accidentally type that instead.
Note also the use of parenthesis to handle the order of operations. You want the modulus of the value after you subtract 65. If you were to try and execute
encrypted_val = plain_val + key % 26
Python would first perform key % 26 and then add plain_val which would not be correct.
Now we want to make it easier to encrypt text without changing our program. We will read from standard input instead of a constant string. To do this, we first need to import the standard library called sys.
import sys
We can remove our Jane Austen quote and add an outer loop
for line in sys.stdin:
# Use .rstrip() to remove the trailing newline character
plain_text = line.rstrip()
One of the biggest pains in python is that white space, especially tab characters, are significant. We need to move all of the internal loop code one more indentation to the left
Now the overall code should look like this:
#!/bin/python3
import sys
plain_text="It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
encrypted_text = ""
key = 13
for line in sys.stdin:
# Use .rstrip() to remove the trailing newline character
plain_text = line.rstrip()
for letter in plain_text.upper():
if (letter >= 'A' and letter <= 'Z'):
plain_val = ord(letter) - ord('A')
encrypted_val = (plain_val + key) % 26
encrypted_text += chr(encrypted_val + ord('A'))
print(encrypted_text)
You can now use the Linux cat utility to test your program. I have a couple paragraphs from the start of "Zen and the Art of Motorcycle Maintenance" that I can encrypt like this:
One thing about using a key of 13 is that it can decrypt just by encrypting a second time. Thus, if I run my encrypted text through the cipher, I should get my clear text:
Last week I attended GUADEC in A Coruña, Spain. While I attend the conference every year, this one was extra special because 14 years ago we held the conference at the same location, and it was my first GUADEC ever. Great memories!
Back in 2012, I was an intern in the Google Summer of Code program, traveling abroad for the first time. Now I feel privileged to have spent all the years since then working on the GNOME project as a professional developer. It turned out to be everything (and more) that my younger self had dreamed of.
Now, living in the Czech Republic, my travel this time was quite smooth compared to my first trip to A Coruña. Vienna -> Madrid -> A Coruña. I managed to leave early in the morning and arrive at the accommodation just in time for the conference’s pre-registration party. Other than the nostalgia of being back in the same Rialta cafeteria, I was super happy to meet some of my long time GNOME friends.
While I stuck to all the talks in the first room, I have now caught up with the room 2 talks via the YouTube recordings. The conference was packed with great desktop content, as always.
On day 1, I would highlight Jakub’s “Symbolic Achievements” regarding the future of our UI icons and Matthias’ recent SVG work. The icon animation work opens up a universe of possibilities for building more polished UIs. At the end of day 1, I went on stage for the “Community Update” session, where I represented the GNOME Settings and the Internship Committee teams.
On day 2, Emmanuele Bassi continued his effort to establish more governance in our project. This inspired me (representing GNOME Settings) and some of the GNOME Shell team to sit down and discuss putting together a Core-Components/System Team. This way, we can collaborate and support each other more effectively across components. As we progress on vertically integrating our desktop experience, our projects become more and more entangled. This requires more and more collaboration and shared responsibilities. We will probably announce this team soon.
Continuing on day 2, Joan presented his progress on passwordless authentication in GDM and Carlos presented an interesting initiative for using Mutter as an application test framework. This could complement other testing methods (such as OpenQA) and help us move away from heavily using the accessibility API for some of our current dogtail-type of UI tests. Additionally, Adrian presented his challenges and ideas for session Save/Restore. This work looks promising and is highly desired by the general audience. This has already been reported on by LWN.
At the end of day 2 I had the chance to present “The Future of Boxes”. A demo of the work I have been doing on the side for the past couple of years to refactor and rewrite Boxes to use a new display widget (libmks), GTK4/libadwaita, and to be a Flatpak-first app. I have a blog post version of this talk coming out in a few days. I’m super excited about the progress I made on this project and how close I feel we are to making it useful for a general audience, just as the “old” Boxes served plenty of users and their workflows.
To wrap up day 2, I hosted our traditional “Intern Lightning Talks” session, where we highlighted the work of our Google Summer of Code interns this season. Two interns managed to attend GUADEC in person, while the other four sent pre-recorded presentations.
Day 3, Saturday, started with a morning-long AGM (the Foundation’s Annual General Meeting). The new format was much more engaging than the ones before. I also would like to praise Allan for doing an excellent job explaining the GNOME Foundation’s processes, finances, and initiatives. After lunch, we watched the traditional “State of the Shell” update from Carlos, Florian, Jonas and Michel. I was also happy to watch Andrea Veri’s update on the state of GNOME Infrastructure, and to learn that our project’s infra is in very good hands during these difficult times.
The local GUADEC organizers put together a lovely dinner experience for everyone. Besides the delicious food and drinks, I spent the night catching up with multiple GNOME friends. This was the same location where we held one of our social events back in 2012. The night sky view of the sea, the fresh air, and the memories were great.
With the three talk days finished, we spent two more days of BoFs/Hackfests. Sunday morning started with my “GNOME Settings BoF”. The session was attended by some well known contributors and also by a few newcomers interested in getting involved or getting answers about the future of our settings. We discussed various topics ranging from the maintenance of some subsystems, AI policy ideas, documentation, and plans for GNOME 51 and 52. I demoed some of my own work-in-progress branches and highlighted what others are working on. I was glad that we received some positive feedback on our recent changes and contributors committed to help review and test some of the work.
At the end of Sunday, I hosted a “GNOME Internship Committee Meetup,” where current and former interns joined Aryan, Maria, and me to discuss how we can improve our internship experience in GNOME. Topics ranged from onboarding and community bonding activities to feedback, etc…
On Sunday evening I went to the Plaza de Maria Pita, the main square in town, to watch the World Cup final between Spain and Argentina. As a football fan, I felt privileged to celebrate this game in the home country of the winning team.
On Monday morning I attended the Design Team BoF, where we discussed various topics, from a transparent topbar in the Shell, to action buttons on dialogs. I started prototyping changes to action dialog buttons for some GNOME Settings dialogs so that the team has something tangible to experiment with. At the end of Monday, my farewell from the conference was participating in the “Engagement Team” BoF. I was happy to see the team getting back in shape again, and how enthusiastic they are. Since I work on Planet GNOME and a couple of other websites, I was happy to help them discuss and develop some ideas for promoting more of our development work through engagement channels (social media accounts, blogs, news reporting, etc…).
On Tuesday, July 21, I flew back home through Barcelona and then Vienna (which is a couple of hours drive from where I live in the Czech countryside).
All in all, I would like to thank the GUADEC organizers for another unforgettable conference, the GNOME community for always raising the bar on the conference’s content, and Red Hat for funding my trip and accommodation in Spain.
Another busy week, another saturday... oh wait, a bit of a delay there.
Read on for why.
Fedora 45 mass rebuild over
The lass rebuild last week finished last sunday, and was merged in on monday.
Overall it was pretty uneventfull from my perspective. No builders dropped out
or had any problems, the upgrade on my rawhide laptop went fine and nothing
really broke, some other folks stepped up and fixed some reporting problems
and all the bugs for failing to build from source got filed.
There were 2 other smaller mass rebuilds that also landed this week:
python had to rebuild a bunch of packages due to a last minute bug
This resulted in a bodhi update with 700+ packages in it, which was
caused a few loading and bw issues, but worked pretty well in the end.
perl had their mass rebuild that was done and merged in. No particular
issues from it.
batcave migration
Our ansible control host/general admin server got moved to rhel10 this week.
Took a fair bit of tweaking. I installed a new batcave02, got it all setup
and data synced to it and then on thursday swapped it in. Overall I think
it went smoothly, and now we have a newer ansible version along with
most everything else.
DMARC mitigation patch deployed
This has been a long standing annoyance for some folks, but I finally
carved out some time to backport a patch and test and deploy things so
that we now (at least on devel, users, devel-announce) are always doing
DMARC mitigation for redhat.com email addresses.
The problem was that externally, redhat.com uses DMARC to indicate
valid senders of the domain, but internally to us, they do not.
So, our mailman instance doesn't think their posts need anything and
sends them out as normal. That results in some users who have providers
that check and reject on that reject those posts.
The patch adds a new admin field to set regex for domains that should
alway be mitigated (that is the email shows as coming from the list
itself instead of the sender email).
So, now we come to why my saturday was so busy sadly.
We are moving our ipa clusters to rhel10. This worked very normally in
staging and there were not any problems.
Production has prooved different. However late this week
Michal, who had been doing the migration got 2 out of the 3
cluster members moved to rhel10. The last one was ipa01, and it
wasn't syncing right. No problem right? We have 2 more servers?
Well, it turns out that ipa01 is 'special' in a lot of places.
We had places where ansible just used the first server, where
a list of servers was given, but 01 was always tried first, etc.
This resulted in a bunch of instability in various things
and was a big pain to track down and fix up.
So, I poked at this friday some (and then a lot more saturday)
and got everything using 02/03. As part of that though, I noticed
what might be the core problem that we were having getting them
moved: we had them using 8GB of ram each, and that was just not
enough. I doubled all of them to 16GB and hopefully that makes
syncing 01 work as expected on monday.
SeedboxSync fait peau neuve côté tooling ! Retour sur la modernisation de mon environnement de dev : abandon du bon vieux Makefile au profit de Just, transition vers pnpm pour un gain de temps spectaculaire côté frontend, et adoption de uv et Ruff pour booster l'écosystème Python. Moins de friction, plus de vitesse : découvrez le détail de cette mise à jour.
Last few years a small team of people in the CLE Team were working each week to prepare a Community update for you. First one published on October 21st 2021. We were starting with only Infrastructure and Release Engineering teams (+ initiatives we did in CPE Team at the time), but later added more teams to our weekly reports to bring people a better picture what is being worked on. We thank to everyone who read our updates and found some value in them.
But as life is going forward even this updates are evolving. Last few weeks @abompard worked together with us to improve his weekly report to include the sources we are using for this weekly reports. So I introduce to you This Week in Fedora as a replacement for Community weekly updates. I’m glad that this initiative I started few years ago was able to live for that long and hopefully helped a few people to find information they were looking for.
I would like to thank people who helped me working on Community weekly updates:
If you look at the bottom of the site now you'll see I have published
a privacy document. Normally I expect updates like this to
explain how somebody is actively trying to track me harder. This is
actually the opposite of that and I hope it can be useful to other
folks who want to get better signal to noise ratio with still
respecting their readers privacy wishes.
It's simple. A tiny bit of unessential javascript loads on each page
load. The javascript checks about 4 different ways to see if you are
asking not to be tracked:
(function (){// If you have asked not to be tracked, stop here. Fire nothing.vardnt=navigator.doNotTrack||window.doNotTrack||navigator.msDoNotTrack;if (dnt==="1"||dnt==="yes"||navigator.globalPrivacyControl){return;}
If that's your wish, it skips. If you leave that open, then it loads a
small invisible svg:
Requests for turnstile.svg are sent to a different log file, and
that's only if apache does not detect the do not track header from
your browser.
If that isn't set then an item is logged in the turnstile log. For
example:
2026-07-24 "https://blog.lnx.cx/privacy/"
That's it. It says on that day, July 24th, a request was made from (in
this example) the privacy page. No time component, only a
date stamp. No IP address. Just a date and a referral page. I can't
use this to line up anything with the other logs to build a profile. I
don't want to.
Putting on my Planet GNOME editor hat for a quick PSA!
Planet GNOME is a convenient aggregator for personal blogs by members of our community. While all content must follow our Code of Conduct, the views expressed in these posts are solely those of the individual authors.
They don’t represent or reflect the opinions of the GNOME Project as an entity or community.
To help highlight this, we’ve added a “Voices of the community” tagline to the website header. It links directly to our “Add feed” section, which also emphasizes that Planet collects the latest posts from personal blogs.
Enjoy the personal insights and variety of perspectives!
Dear testers, we're happy to announce Kiwi TCMS version 16.2!
IMPORTANT:
This is a minor version release which includes multiple security related updates,
several improvements, database migrations, API changes and bug fixes.
While you (yes, you! no, not you, the one behind you) have been sweltering in
the heatwaves of the northern hemispheres (Assisted-by: AI), I've been busy
adding graphics tablet support to libei. This is scheduled for the soon to be
released libei 1.7.0.
The initial work was done by Jason Gerecke and Josh Dickens from Wacom, I've
been extending, polishing and testing it for the last few weeks.
Also, upfront: this only covers the stylus part of a tablet, we do not yet have
an implementation for the "pad" part (the buttons, dials, rings, strips).
libei is, of course, the library for Emulated Input, a good-enough transport
layer for sending logical input events between processes. We're already using
libei as part of the XDG Portal Remote Desktop and Input Capture portals where
we've been busy hurtling key and pointer events between the participating
parties (and soon gesture
events and text).
In the next release of libei, we will now also have "ei stylus" capabilities, i.e.
the ability to send tablet stylus events. Getting pointer, keyboard and touch events
supported was a long undertaking, everything was new and shiny and needed to be
added everywhere in the stack. Now that all this is in place, scuffed and scratched,
adding tablet events will be quite simple.
The ei stylus interface
Here's a short outline of how libei handles tablet events because it is, of
course, different to how libinput handles them. Logical events are much nicer
after all than physical hardware events.
First: we have a new interface: "ei_stylus". An EIS implementation (e.g. your
compositor) may provide you, the libei client, with a device that supports this
interface and one or more associated regions (typically representing the
available screen areas). Typically this will be a separate device to the
pointer devices or the keyboard devices but it's not a requirement. The
ei_stylus interface comes with a bunch of capabilities you'd expect from a stylus
(tilt, pressure, distance, ...) that you can selectively enable to emulate the
stylus you want to. So basically, EIS will say "here's a stylus device, I support
pressure, tilt, rotation, ..." and then the libei client says "This stylus should have
pressure and tilt but nothing else". And then you do the normal thing: send
proximity events, send tip down/up events, send data for the various
capabilities you've enabled.
Happily for the EIS implementation, libei forces the client to take the
guesswork out of everything: if you select the pressure capability, you must
send a pressure value when coming into proximity. Where libei is used to
forward data from a physical stylus (e.g. via some remoting protocol) it is
up to the client to deal with firmware bugs that e.g. won't send data
until a few frames in.
Note that there is no "tablet" anywhere. The tablet is represented by the
region that the device may interact with. So in some ways every tablet is an
on-screen tablet (which makes sense since we have logical events).
Multiple styli
The only quirky thing is how to request multiple styli[1]: libei 1.5.0 has
added a "request device" request that allows a client to say "hey, EIS, I
want a new device with capabilities pointer, keyboard, ...". And, if you've
been a nice client, minding your own business, the EIS implementation may
just create such a device for you.
So for the case of multiple styli: if the default stylus (if any) isn't
good enough, you can now tell EIS that you want a(nother) device with stylus
capability, configure the stylus capabilities once the device shows up
and voila, you now have a normal pen, an art pen and maybe even an airbrush
represented as logical device in libei. And since they're all separate
devices in the protocol, they can be individually tracked and used, much like
libinput tracks individual styli.
[1] For the "lots" of users that actually use multiple styli...
libei 1.7.0 (to be released soon) comes with a new interface: "ei_gestures"
which, creatively, will allow for gestures to be sent between a libei client
and an EIS implementation (typically: a Wayland compositor).
I'm not going to go too deeply into how pinch, swipe and hold gestures work, suffice
to say we've had those in libinput (for touchpads) for years now so compositors
and toolkits should already support those. And since libei and libinput have
vaguely equivalent API layers integrating gestures for libei devices in
compositors should be fairly straightforward.
The plumbing layers in the portals exist already too, so adding gestures to libei
means that - once the compositors support it - we can have gestures support
in remote desktop and input capture implementations without needing to update
anything else. Hooray! Join in with me. Hooray! Louder! HOORAY!
For testing I had a (vibe-coded and thus immediately abandoned once testing was complete)
gesturemouse utility which
translates input events from a mouse into gesture events (depending which
button is down). But don't let my lack of be a limit to your imagination, I'm
sure you can come up with good use-cases for this.
If you've been paying attention (and I know you have, because it'd be
embarrassing for you if you didn't) you'd have noticed that libei 1.6 (May
2026) added support for keysym and text events.
libei sends logical events between a libei client and an EIS
implementation (typically: a Wayland compositor) but the keyboard
interface it had was designed like real keyboards: key codes together
with an (XKB) key map. You press one key, the keymap decides what that
key means on the compositor side and off we go. This is easy but not always
useful.
As of 1.6.0 libei now also supports an "ei_text" interface. A compositor
may choose to provide you[0] with a device that supports this interface
and that gives you two really nice opportunities.
First, you can now send a key sym. Instead of sending the KEY_Q
key code and hoping it actually translates to 'q' (and if there's e.g. a
frenchman^Wfrenchperson lurking behind the keyboard it may mean 'a'), you can
now send 'q' as actual keysym. Or 'Q' instead of sending shift+q and
hoping for no french influence in the process. It becomes the EIS
implementation's job to handle that keysym - if it's a shortcut it may handle
it directly, otherwise it may pass it on via Wayland to an application[1]. This
centralises the keysym to keycode handling in the EIS implementation which is a
pain for compositor authors (though they likely have that code already for e.g.
RDP support) but reduces the variety of differently-wrong implementations in
clients and of course makes it so much simpler to write clients.
Second, a client can send UTF-8 text to the compositor. So instead of
emulating shift, keycodes, etc. you can literally send "Hello World"
and expect the EIS implementation to pass that one. Again, makes a bunch
of utilities a lot simpler to write and I mostly leave it up to your
imagination to figure out what to do with that.
Notably for both cases: libei is about logical events that have a specific
meaning that do not need further interpretation. If a client sends 'Q'
that means it is supposed to be an uppercase Q. Sending keysym Shift_L and Q makes
little sense. And for the utf8 text events: how the text comes to
be matters doesn't matter for libei so you may use an IM to make up the text to
begin with and send it, once committed, to EIS. It's not for sending partial
strings.
As mentioned in the
previous post: the plumbing for this is already in place so both clients
and compositors can add support for this new interface without having to bother
the rest of the stack (e.g. portals). So, hooray I guess.
The text/keysym support is relatively recent so expect this to hit the next compositor version (or the one after that).
[0]: the EIS implementation decides which devices are available and arguing about
this is even less useful than arguing with a world cup ref
[1]: after converting it to a key code with possible keymap changes... but hey, such is life
Turns out it's been years since I've talked about eggs, so let's change this.
libei is, of course, the
library for Emulated Input[1].
This post is mostly a refresher because it's been so long and a short summary
of some of the work we've done so far, in preparation for some more posts that
come soon.
libei is a transport layer for logical input events, unlike
libinput which is a hardware abstraction layer. In libinput's case the
device's firmare/kernel pass events that are somewhere on the sanity spectrum,
libinput tries to make sense of those and then we convert those to logical
events to be consumed by the next layer (typically the Wayland compositor or
Xorg). This is how e.g. "touch down at position x1/y1, touch up at position x1/y2" is
converted into a button click event if touchpad tapping is enabled. Or maybe
into nothing if we find it was an accidental palm touch.
libei works purely on the logical level - you as the libei client pass
logical events to the EIS (Emulated Input Server) implementation (typically
the compositor). No guesswork, you say button click, EIS gets a button click.
libei supports a "sender" and "receiver" mode, depending on whether events are
sent to the EIS implementation (input emulation) or receive from the EIS
implementation (input capture). libei is designed for the Wayland stack but there
are zero requirements for Wayland on either the client or the EIS implementation.
Core to libei's design is that the EIS implementation is in control of
virtually everything, it decides which devices are available to the client,
when those devices can send events, etc. Much like the compositor is in charge
when it comes to physical devices - if a compositor decides a physical device
doesn't exist, a Wayland client cannot get events from it.
Since the original proposal (again, [1]!) we've been busy bees and libei
is now a part of the XDG Remote Desktop portal and the XDG Input Capture
(both since version 1.17, mid 2023). In both cases the portal is for the
negotiation and initial agreement of what should happen, libei is then used as
the transport layer between the two processes [2].
More recently we also added session persistence support so you don't have
to allow access on every connecton. Much of the work enabling this was done by
Jonas Ã…dahl, it is now in the portals since version 1.21.0 and should be in
the major compositors in the current or next versions.
Plumbing the Pipes
Getting all this into place was a huge amount of work across several pieces of
the stack. This isn't exciting in the same way as laying plumbing pipes isn't
particularly exciting but much like regular plumbing: once it's in place you
can change your diet without severely impacting everyone again. Try get that
analogy out of your head now. You're welcome.
In libei's case this means three things:
if you have a client that uses the XDG portals to send/receive events
they will now work with any compositor that implements the portal. No need
for GNOME/KDE/... specific APIs.
if you have a compositor that implements EIS you have all the infrastructure
in place to talk to libei clients from somewhere else, if need be. The
use-cases for this aren't fully scoped yet (assisitive technologies, virtual
keyboards, touchpads, etc?) but the piping is there and ready to be (ab)used .
since the actual events back and forth don't affect the layers in between,
we can now add new events to libei without having to change everything else
again.
Let's look at how this works in practice.
The XWayland XTEST use-case
An example for such a case where we can now abuse the piping is Xwayland
support for XTEST. XTEST is the protocol that everyone uses to emulate input
under X but in Wayland it's not hooked up to anything so those APIs simply
won't work.
But what we can do in Xwayland is translate XTEST to libei events and
facilitate the portal interaction. This means our stack looks roughly
like this:
+--------------------+ +------------------+
| Wayland compositor |---wayland---| Wayland client B |
+--------------------+\ +------------------+
| libinput | EIS | \_wayland______
+----------+---------+ \
| | +-------+------------------+
/dev/input/ +-----------| libei | XWayland |
+-------+------------------+
|
| XTEST
|
+-----------+
| X client |
+-----------+
And if said X client uses XTEST to try to emulate devices, Xwayland will
ask the Remote Desktop portal for permission and set up the session, then pass
the XTEST events on as libei events and voila - your 20 year old X client can
send pointer and keyboard events through an XDG Portal without knowing about
it (and the user can prohibit this and even gets some information on who is
sending events which is not possible with normal XTEST at all). This has now
been supported since Xwayland 23.2.0. Compositors don't need extra support for
this.
What's next
So we have a lot of the plumbing in place, or in another anology: we have a
hammer, let's go looking for nails. And right now the nails we can see are
sending text, gestures, and tablet support. And those will be the subject of
the next few posts.
[1]: 6 years ago?! whoah...
[2]: in Remote Desktop's case replacing the DBus emulation APIs which were a Newton's Cradle of wakeups for at least 4 processes per event
SiteGround is a technology company founded in 2004 that helps individuals,
entrepreneurs, and businesses build and grow their online presence.
Our goal is to provide customers with the tools they need to create, manage, and grow their online businesses from a single platform.
Over the years, SiteGround has built a strong engineering culture focused on
performance, reliability, innovation, and customer experience.
This continuous focus on technology and quality has helped us support millions of websites and businesses worldwide.
Tell us more about SiteGround's product lines?
SiteGround has evolved far beyond traditional web hosting.
Our platform includes web hosting, managed WordPress hosting, cloud infrastructure,
Site Tools, website-building solutions, ecommerce platforms, professional email services,
email marketing products, and AI-powered solutions.
These products serve a wide range of users, from individual creators and small businesses to agencies and larger organizations.
From a technical perspective, our products are built using a diverse technology stack
that includes PHP, Python, Go, TypeScript, React, containerized environments, and cloud technologies.
How about SiteGround's relation to open source?
Open source has always been an important part of SiteGround's engineering culture.
Many of the technologies that power our products are built on open source foundations,
and we actively support the open source community through sponsorships, community involvement,
and contributions to projects that help power the modern web.
We strongly believe that open source software promotes innovation, transparency, collaboration
and accessibility. We are also strong supporters of the WordPress ecosystem.
One of the advantages of using open source software is the ability to collaborate directly with maintainers,
contribute improvements, and tailor solutions to real-world needs.
An improvement from SiteGround's Martin Bodurov has already been merged into Kiwi TCMS.
One of the biggest challenges is the breadth and diversity of our product portfolio.
Our teams test everything from hosting infrastructure and website management tools to
ecommerce solutions, email marketing platforms, and AI-powered products.
These products are built using different technologies and often rely on complex integrations
and shared infrastructure. A change in one area can potentially affect multiple systems,
which makes regression testing, coverage visibility, and traceability especially important.
Another challenge is balancing the speed of delivery with the level of quality and reliability
our customers expect. As our platform continues to grow, maintaining confidence in releases requires
a combination of structured testing practices, automation, and close collaboration between
engineering and QA teams.
How do teams at SiteGround approach testing?
Testing starts with understanding the requirements and acceptance criteria for a feature.
Before execution begins, we define a lightweight test plan that outlines the areas we want to validate,
potential risks and the overall testing scope.
During testing, we maintain testing notes and a testing journal where we document findings, observations
and scenarios that deserve additional investigation. Both the test plan and the testing journal go
through a review process, helping us share knowledge, improve coverage, and ensure consistency across the team.
The approach combines structured validation with exploratory testing techniques,
allowing us to adapt as we learn more about the feature.
Detailed test scenarios are created and maintained in Kiwi TCMS. These scenarios serve both as
validation artifacts and also as long-term documentation and a knowledge base for the organization.
As features mature, many of these scenarios become candidates for our Playwright automation.
Automation plays a central role in our testing strategy.
We maintain extensive automated coverage across different layers of the testing pyramid,
including unit, integration, API, end-to-end, visual, accessibility, and performance-related testing.
Automated regression suites are continuously executed through our CI/CD pipelines,
helping teams identify issues early and maintain confidence in every change.
The combination of structured manual testing, peer reviews, automation,
and continuous regression automation execution allows us to maintain quality while supporting a fast development cycle.
What other technologies does testing at SiteGround involve?
Testing at SiteGround relies on a diverse ecosystem of tools that support automation,
reporting, traceability, and continuous delivery. Our end-to-end automation is primarily
built with Playwright, while reporting and execution visibility are provided through
Allure Report and our CI/CD pipelines. We also maintain dedicated checks for visual regressions,
accessibility validation, and website quality metrics using tools such as Lighthouse.
To support fast feedback cycles, our automation infrastructure is optimized for containerized
execution on Google Cloud Platform, allowing us to execute large regression suites efficiently and at scale.
Where does Kiwi TCMS fit into SiteGround's overall testing infrastructure?
Kiwi TCMS serves as the central repository for testing knowledge and traceability within our organization.
While our automation execution, reporting, and CI/CD processes are handled by other tools,
Kiwi TCMS acts as the place where testing knowledge is documented, maintained, and shared across teams.
It stores our testing scenarios, helps us understand what has already been automated,
and provides visibility into overall test coverage. By maintaining a clear relationship between manual test design
and automated validation, it helps us ensure consistency as our products and automation suites evolve.
Kiwi TCMS integrates into our broader testing ecosystem and it is the source of truth for testing knowledge.
It provides traceability between requirements, documented scenarios, and automated validation,
while also serving as a valuable source of context for engineers and AI-assisted development workflows.
Why did you decide to use Kiwi TCMS?
Before selecting Kiwi TCMS, we evaluated both commercial and open source test management solutions.
While many products offered a wide range of features, we were looking for a solution that was flexible,
practical, and aligned with the way our teams work.
Kiwi TCMS stood out because it provides the core functionality we need without unnecessary complexity.
Rather than focusing on heavily marketed features that we would rarely use,
it offers a clean and efficient approach to test management, traceability, and knowledge sharing.
Its open source nature was another important factor. We value the flexibility that open source software provides,
whether it's adapting workflows, building integrations, or contributing improvements back to the project.
This gives us confidence that the tool can evolve together with our testing needs.
Tell us how you've integrated Kiwi TCMS with Playwright and Allure Report
One of our goals has been to maintain strong traceability between documented test scenarios and automated validation.
The scenarios stored in Kiwi TCMS often serve as the foundation for our Playwright automation.
To preserve this connection, we include Kiwi TCMS test case identifiers in the Allure Report metadata
of our automated tests. This provides a consistent mapping between documented scenarios and automated coverage,
making it easier to understand which tests validate which requirements and features.
Having this relationship available directly in the test metadata helps us identify coverage gaps,
keep documentation aligned with implementation, and navigate easily between automated tests and their corresponding
Kiwi TCMS scenarios.
Over time, we have also built custom integrations around this model.
One example is a custom Playwright reporter that can read Kiwi TCMS identifiers from the Allure Report metadata
and correlate automated execution results with the corresponding test cases in Kiwi TCMS.
The exact implementation continues to evolve, but the primary objective remains the same:
maintaining a clear connection between test design, automation, and execution results.
Tell us more about your internal "Kiwi TCMS API Client" script
The internal "Kiwi TCMS API Client" started as a simple wrapper around the well-structured Kiwi TCMS API.
Initially, it was created to support integrations between our automation ecosystem and Kiwi TCMS,
helping us automate parts of the test result synchronization process and reduce manual effort.
Over time, its role evolved beyond automation integrations.
Because Kiwi TCMS serves as our central repository of testing knowledge,
this API client became a convenient way to expose that information to other tools and workflows.
More recently, we have also used it as part of the tooling that supports AI-assisted development and testing.
By giving AI tools controlled access to test scenarios and testing knowledge stored in Kiwi TCMS,
we can provide better context when generating test cases, automation code, or other testing-related artifacts.
This internal client remains intentionally lightweight, focusing on simplifying access to Kiwi TCMS data
and enabling integrations without requiring every other tool to interact directly with the API.
Tell us how does using AI in testing fit in relation to Kiwi TCMS?
Yes, AI has become an important part of our daily engineering and testing workflows.
We use tools such as Codex, Claude Code, and Cline to assist with a variety of tasks,
including test case generation, Playwright automation development, code reviews, documentation,
technical research, and day-to-day development tasks. These tools help us accelerate routine work
and allow engineers and testers to focus more on quality strategy, risk analysis, and problem solving.
Kiwi TCMS plays an important role in this process because it serves as our central repository of testing knowledge.
The scenarios and documentation stored there provide valuable context for both engineers and AI-assisted workflows,
helping ensure that generated test assets remain aligned with documented requirements, expected behavior, and existing coverage.
For example, when working on automated tests, AI tools can help us generate or refine Playwright implementations
based on the scenarios stored in Kiwi TCMS. Having access to well-structured testing knowledge
significantly improves the quality and consistency of the generated output.
Rather than treating AI as a replacement for testing expertise, we see it as a force multiplier.
Combining AI-assisted development with well-maintained testing knowledge in Kiwi TCMS allows us to
work more efficiently while maintaining consistency and quality across both manual and automated testing efforts.
If you like what we're doing please help us grow and sustain development!
Red Hat Konflux team offers several AI agents via project
fullsend. They triage issues, write
patches, and review PRs (and more!) directly inside GitHub Actions.
In Packit, we’ve decided to give Fullsend a try and onboard our python gitforge
library ogr to it.
This is my experince with the onboarding process (which is not trivial) and a
first few runs. Buckle up!
As usual, most of the work was done from within a Claude Code session and then
I just let Claude to write the rest of this post.
Due to the increase in AI-generated security vulnerability reports, it is time for some changes in how GNOME manages vulnerability reports.
These policy changes intentionally do not distinguish between reports that contain AI-generated content and those that do not. Following the same rules for all vulnerability reports is simpler than having two different ways of doing things. Reporters rarely disclose AI use, and it’s nice to not have to guess whether the issue report is AI-generated or not; it’s normally obvious, but not always. Also, vulnerability reports that are not discovered by AI are becoming increasingly rare. Non-AI reports are now moderately unusual, so it really doesn’t make sense to optimize for them.
Reduced Disclosure Deadline
Traditionally, I have applied a 90 day disclosure deadline to all security issues reported to GNOME Security. 90 days is an industry standard timeline, but it doesn’t work particularly well for GNOME. In practice, almost all GNOME maintainers handle vulnerability reports in one of two ways:
The project maintainer fixes the issue quickly, typically within 1-3 weeks after it is reported.
The project maintainer does not fix the issue at all. The issue report eventually reaches the 90-day disclosure deadline, at which point I unset confidentiality.
The 90-day deadline is intended to allow project contributors time to fix the issue before it becomes public, but in practice, maintainers do not actually make use of most of this time. I disclose the issue report and request a CVE when it is fixed or when the disclosure deadline is reached, whichever comes first. Once a CVE is assigned, contributors who are not regular project maintainers will sometimes attempt to fix it. Accordingly, keeping the issue reports confidential for 90 days only introduces a delay that is not useful.
Some other projects, notably the Linux kernel, have implemented an immediate full disclosure policy for issue reports that seem to be AI-generated, on the basis that a vulnerability that can be discovered by AI is presumably already known to attackers. But this policy seems pretty extreme, and is certainly unkind to maintainers who might feel pressured to urgently fix the issue. Immediate disclosure would not work well for GNOME.
Instead, I will switch to a 30 day disclosure deadline for issues reported on August 1, 2026 or later. This seems like a good compromise. The shorter deadline would probably work better for GNOME even if not for the increase in AI-generated issue reports.
Procedure for Projects that Prohibit AI-Generated Content
If a project prohibits issue reports that contain AI-generated content, I will no longer forward security issues reported to GNOME Security to the project’s issue tracker, since the overwhelming majority of vulnerability reports contain AI-generated content and would violate the project’s policy. Instead, I will immediately close the issue report in the GNOME Security issue tracker, then ping the project maintainers to let them know about the existence of the report. If you prefer to receive vulnerability reports in your project’s issue tracker, then please change your project’s AI policy to make an exception for vulnerability reports.
Unfortunately, GNOME maintainers don’t have access to confidential issues in this issue tracker, and GitLab does not allow CCing individual developers on confidential issue reports. I had been planning to adopt immediate disclosure for these issues only, but perhaps we should instead expand the permissions to allow all GNOME developers to see the issue tracker. Opinions welcome.
Moving On
I have been managing GNOME security issue tracking since November 2020. (Thank you to Red Hat for supporting this work.) Security tracking is largely a secretarial duty: I keep track of issues when they are reported and when they are closed, disclose them when the deadline is reached, and request CVEs when appropriate. It is not a huge amount of work, but I am getting tired of it, so it’s time for a change. I will discontinue tracking newly-reported security issues on November 1, 2026. During November, I will focus only on tracking issues reported prior to November 1. By December 1, all disclosure deadlines for that set of issues will have been reached, and I will be done.
Currently nobody else is tracking GNOME security issues. If you are an experienced GNOME community member and you are interested in taking over this work, let me know and I will help you get started. (Security tracking is not a good task for newcomers.)
This may also be an opportunity to improve our tracking infrastructure. I use a wiki page, but this is fairly primitive and requires considerable manual upkeep. It’s easy to forget to update the page when an issue report is closed, for example. Ideally, we would replace the wiki with a proper web app that dynamically updates based on the actual state of the issue.
I use Home Assistant, and for text-to-speech (TTS) I’ve been running Piper through Wyoming Piper.
Piper is a fast, local neural TTS engine originally built for the Rhasspy project and now maintained by the Open Home Foundation. It’s designed to run entirely offline, even on modest hardware like a Raspberry Pi.
Wyoming is the open protocol Home Assistant uses to talk to voice components like TTS, speech-to-text, wake word, voice activity detection (VAD, which decides when someone has started or stopped speaking) over the network, so any service that speaks Wyoming can be plugged in as a satellite. Wyoming Piper just wraps Piper so it can be served this way.
Both work well and I have no complaints about reliability. My issue is quality: the German voices aren’t great. Piper depends on open datasets for training, and good open German speech data is scarce, so the German models lag behind the English ones. I also run TTS locally on my desktop for event reminders, so voice quality matters to me beyond just Home Assistant.
Looking for something better
I wanted better output quality, so I started looking at alternatives and found Crane, a Rust inference framework built on Candle.
An “inference model” is a trained neural network used to actually produce output like text, speech, an image, rather than to learn from data (that’s “training”). An “inference framework” is the software that loads such a model and runs it efficiently: managing GPU/CPU memory, batching requests, and exposing an API around it. Piper and Crane are both inference frameworks.
Crane already had Qwen3-TTS support, and its Serena voice’s German output sounded noticeably better. I also wanted to try Voxtral-4B-TTS-2603, Mistral’s open-weight TTS model, so I added support for it. Voxtral TTS produces expressive, natural-sounding speech across 9 languages including German, with low time-to-first-audio and streaming support. It is a good fit for a voice assistant that needs to start speaking quickly.
Adding Wyoming support
Once Voxtral was working in Crane, I built crane-wyoming, a standalone Wyoming protocol server, so Home Assistant could use these models as its TTS service. To make that possible, I added the Tts trait and the surrounding TTS abstractions to Crane, since there was no stable interface for driving a TTS model on its own, separate from Crane’s full inference engine (tokenizer/LLM/VLM machinery). Those abstractions have since been merged upstream: lucasjinreal/Crane#44.
crane-wyoming depends on Crane only for that Tts trait and the concrete model types it needs to construct, not Crane’s engine crate. So it carries its own small TTS-only model runtime (one dedicated worker thread per loaded model) and its own on-disk response cache.
The project grew into a small Cargo workspace. Besides the Wyoming server itself, it now has cw-say, a standalone CLI client for scripting.
It also has sd_crane_wyoming, an output module for speech-dispatcher. speech-dispatcher is the common Linux TTS abstraction layer that screen readers like Orca, and other accessibility tooling, talk to. It launches output modules as subprocesses and speaks to them over stdin/stdout, using its own line-oriented, SMTP-style protocol. sd_crane_wyoming translates that into Wyoming requests against a running crane-wyoming server. That way, the same server process and cache serving Home Assistant can also serve the desktop. After registering it in speechd.conf, spd-say -o crane "..." works. So does anything else built on speech-dispatcher, like Firefox’s “Read Aloud” or Orca itself. All of it gets the same voice quality as Home Assistant, without running a second TTS backend.
What’s next
Speech-to-text. I’ve added Qwen3-ASR support for utomatic speech recognition (ASR) into Crane. This needs to be wired in crane-wyoming next. Also Voxtral-Mini-4B-Realtime-2602 is interesting.
VAD. Crane already has a Silero VAD implementation. Adding it for STT is straight forward.
Wake word. Once VAD is in place, add Open Wake Word support or similar.
With all of that implemented, you’d have a complete self-hosted Wyoming voice stack with no cloud dependency.
Current limitations
The catch is that you need a GPU to run it well.
If you only need TTS for occasional things like reminders, short announcements, running it on CPU with caching is enough, since repeated phrases just get served from cache instead of resynthesized.
All of this is for advanced users and hackers right now. There’s no polished packaging yet. Systemd units exist for both system and user services, including socket activation, but you still have to build from source.
Another week, another saturday post recaping things. :)
RHEL10 migrations
Bunch more things reinstalled with RHEL10 this last week. Made
some good progress. We are soon going to be down to the 'tricky'
ones that will require an outage. So, there will likely be
an outage or two in upcoming weeks to knock those out before
Fedora 45 branching.
Fedora 45 Mass rebuild
The mass rebuild for f45 started this last week and seems to be moving
along fine. Of course s390x is the slowest arch, but thats not
unexpected.
I did manage to update all the builders and reboot into the latest
kernel before the mass rebuild started, along with updating to
koji 1.36.1. So far no builders have dropped off or failed that
I am aware of, which is nice.
DNS and geoip
This last week we noticed that out dns geoip setup wasn't updating
correctly and had some pretty old data in it. This may have been
causing some network blocks in some regions to go to proxies
that are... not in those regions. ;(
Thanks to work from Vit Smolík, it's now updating correctly.
So, for some fedoraproject.org services hopefully some folks will
see improved performance with web application access.
I also added memory to some proxies and removed some from the
EU zone that were not really in EU.
Release Candidate versions are available in the testing repository for Fedora and Enterprise Linux (RHEL / CentOS / Alma / Rocky and other clones) to allow more people to test them. They are available as Software Collections, for parallel installation, the perfect solution for such tests, and as base packages.
RPMs of PHP version 8.5.9RC1 are available
as base packages in the remi-modular-test for Fedora 42-44 and Enterprise Linux≥ 8
as SCL in remi-test repository
RPMs of PHP version 8.4.24RC1 are available
as base packages in the remi-modular-test for Fedora 42-44 and Enterprise Linux≥ 8
as SCL in remi-test repository
ℹ️ The packages are available for x86_64 and aarch64.
ℹ️ PHP version 8.3 is now in security mode only, so no more RC will be released.
I’ve tried several gaming oriented Linux distributions and found them all to be… well, to be frank, bloated and unstable. I seek the most minimal experience, secure, up to date, with a comfy desktop environment for a small screen. Most distributions are full of preinstalled stuff that you will never use, some of which often runs in the background, quietly eating away at your battery life. I also really like the ability to “tab out” of my game and have discord, browser, or anything else immediately available, without unreliable 3rd party plugin managers for steam that are broken every single time you want to play a game (yes I’m looking at you deckyloader). Simply I want my handheld to be ready to game, no matter how often I use it. Daily, or once a year, without having to deal with mandatory updates breaking everything.
For the longest of time I used Fedora KDE that would boot straight into the gamescope steam. Relatively recently I acquired a new mini laptop where I went with Fedora minimal + Niri + Noctalia and I love this setup. This article describes my configuration that can be applied to any laptop, or a handheld gaming console, with small differences. And I’ll be writing it as I apply it to my GPD Win4. Please note that this configuration is not for a beginner windows-refugee. You’d be better off with KDE if you need a lot of floating windows on many displays, or if you’re a beginner.
Linux Distro
Why Fedora? Because it’s one of the most stable Linux distributions and at the same time one of the most up to date distros with the latest toys available. We will be using minimal install, without any desktop environment. (Note that it doesn’t even install wifi drivers so you will need ethernet, or a usb stick to install those.)
Grab yourself a Fedora Everything iso and apply it onto your USB stick/dongle/goober of choice with Fedora Media Writer(available in your linux software center, flathub, etc.)
The good old fedora installer will guide you through everything, just select Zero checkboxes on the software selection screen :) Minimal. For laptops or other portable devices, use LUKS encryption. Otherwise default btrfs partitions are fine.
The first steps post install
You’re gonna boot into basic tty command line interface. If you have ethernet available, install your wifi drivers.
If you don’t have ethernet, you’re gonna have to find the rpm and shuffle it over with a usb stick.
Now the next thing that I configure is mounting my NFS share which I can then use to easily transfer some files, such as my do-it-all script which enables all my repositories necessary, installs all rpms, enables flathub, installs my flatpak apps, and clones my chezmoi configuration files for everything. At this point my install is done. I’ll help you with yours though :)
A little disclaimer - I am using a handful of copr repositories which are “user generated” packages without the same security and quality assurance that the main Fedora repository enjoys. Kind of a “use at your own risk” situation - you should always verify the author and use their packages only if you trust them. I trust those that I use (some of which are my own).
Install Everything
rpmfusion
RPMFusion repositories are necessary for other packages as well, but also useful for multimedia and nvidia. Enable them either way.
Fedoratricks is a collection of scripts that we (the Fedora Discord) have put together to help new users with the basic Fedora setup and diagnostics - to help us in providing support to you.
Enable the copr repository:
sudo dnf copr enable rhea/fedoratricks
Install the package
sudo dnf install fedoratricks
Use it to enable rpmfusion:
fedoratricks rpmfusion install
You can now use it to install multimedia/codecs, or even nvidia drivers if that’s what you have. Simply run $ fedoratricks --help to figure it out :)
Manual steps - take it from the horses mouth directly:
UPDATE: As of f44 noctalia is now included in its core repositories, if that’s your situation, you can SKIP the terra repository configuration below and install it directly.
Terra repository is our source of noctalia packages. Beware though, it is known to cause issues if you leave it enabled. We will restrict it only to install the relevant packages.
Here is a complete list of things that I personally install on my handheld (both laptop and gaming) - feel free to use it to experiment with chezmoi, wezterm, neovim and ble.sh - or delete the things you don’t want.
Wezterm solves a few issues for me which many of the GTK based terminals cause.
Enable its copr $ sudo dnf copr enable wezfurlong/wezterm-nightly - otherwise remove it from the below command.
Another one included below is neovim - it’s great, you’re welcome :D No seriously though, you can remove it as well as npm fd-find ripgrep if you do not want to use it. If you do, you will need to also sudo npm install -g tree-sitter-cli and if you want tips on nvim plugins, message me.
Some of these packages are simply dependencies for other things, or necessary applications to exist in a minimal non-DE setup, and it also includes niri which we’ve omitted so far.
Install your desired flatpaks. For gaming, since that’s our focus here, you’d want at least protonplus (and probably a web browser - the above didn’t include one)
flatpak install protonplus
XDG configuration
This is by far the most tricky thing to do on this kind of install. Necessary packages should already be there, now you need to configure them - Arch Wiki reference
(Create its directory and) add into the following file:
Assuming you did install it. I won’t go into the details of why I have these, alas this is my preferred configuration. (I don’t like menu autocomplete.)
You can simply create an alias for this in your .bashrc for that btrfs-assistant doesn’t work out of the box without a DE. This is my workaround. Execute it and use btrfs assistant to configure your snapshots for both root / and /home, after you reboot and have some GUI :)
alias btrfs-alias='xhost +; pkexec btrfs-assistant; xhost -'
Auto-start Niri
Add at the end of your .bashrc
if [ "$(tty)" = "/dev/tty1" ]; then
echo "niri?"
niri --session
fi
Configure Niri
A must-have is autostart for noctalia shell. Optionally configure some keybinds and what not.
mkdir -p ~/.config/niri
Grab (wget) the default config and shove it into ~/.config/niri/config.kdl
You should probably run niri validate after messing with your config file.
Some things you can add or configure, I’m sure you can figure it out what’s what based on this example:
Technically all of the above can be done without a single reboot in tty - but you are now ready to reboot into your niri session.
After you reboot into niri/noctalia, configure your noctalia using its gui settings and under the Colour Scheme “tab” create templates for qt, gtk, niri and kcolorscheme
You will need to add include "noctalia.kdl" into your niri config for these to be read.
Then run the qt6ct application and simply select the noctalia theme and confirm. You should be all set now. If for some reason dolphin doesn’t use your theme, you may have to set it there manually. Dolphin is a special snowflake like that.
steam
I personally execute the entire Steam in gamescope on my handheld with the deck bigpicture mode. You can auto-start it as well. (Just keep in mind that Steam will update itself in the background so it may take minutes for it to actually show up if it’s updating.) Add into your niri config:
Since we’re still waiting for valve to fix gamescope touch input and nointro, you will need to run Steam without gamescope if you need the touch input. And you can use a black frame webm to get rid of the intro video as well, grab it and shove it into: ~/.steam/root/config/uioverrides/movies/deck_startup.webm
I just wanted to create a playlist I can listen to that will most likely have a
solid selection of songs I'm going to hear August 13/14/15. I ended up with a
prob and stats model that has produced close to 90% accurate predictions (citation needed, see "Context" below).
Back in February this year (2026) my Uncle Tim
and I caught the first 2 nights of the opening run of
moe's "Born to Fly" tour, at Higher
Ground in Burlington, VT.
It was great. My only note: I wish we had realized sooner that it was 3 nights,
not 2.
Going into that (unforgettable) experience I felt pretty confident in my
knowledge of moe's catalog. They've been around for about 35 years and primarily
tour, so that's a lot of potential music to keep up with. I was mistaken. There
were a lot of songs they played those two frigid Burlington nights that I wasn't
familiar with. And that's cool, ya know? You're allowed to play music I'm not
familiar with.
At the time I didn't feel like I got everything I wanted out of it.
Because of the hard work of the tapers like Phil
Hernandez I've
been able to listen to those two nights on repeat (and the third night we
missed) and it's even better than what I remembered. Which was, to be completely
honest, already pretty fucking great.
OK let me stop burying the lede. This update is about the weeks of work I've put
into some data analytics/modeling/probability software. Basically "setlist.fm
but better". I'm going to do my first "follow the band" trip in August and I
wanted to be sure I was familiar with enough of their recent touring catalog to
not get taken by surprise again. It's just how I enjoy music. Don't knock it.
So I made a few things.
My objective was to create some kind of script that will generate a pool of a
few dozen songs that are most likely to play on the 3 night run I'm catching
them in August. All I wanted was to create an actual playlist (on the computer)
that I can listen to that probably covers most of what I might hear (songs I
wasn't prepared for).
It turns out once you build that foundational model and data pipeline you can
build a lot of other prob and stats stuff with very little extra effort. And
when you add an LLM assistant, you can accelerate that like whoa.
The Scorecard is a prettier and more useful
version of the first iterations of what the model was producing. This version
keeps history and shows you how the predictions change over time as more results
come in and the model is able to improve its predictions.
Here are examples of two nights side by side. You can already see that there's a
lot of data in this. It's a lot more interesting if you load the page and
explore it yourself.
The model ingests data from 3 sources.
Archive.org API
Setlist.fm API
Machine vision parsing Instagram posts
Data ingestion is weighted in that order. We prefer to build nightly data based
on taper uploads in the moe. collection on
archive.org. We supplement that with data from setlist.fm
when archive is lacking. And if all else fails we fall back to me personally
feeding a Python parser data from their Instagram
page.
Speaking of data. Did you notice that pretty little building icon? Let me show
you a closer screenshot:
As we parse new data we update the database. That means that when the
predictions are updated we're able to automatically update all churn tables to
give you links to recordings we found on archive.org when we were building the
data set. Obviously this information is not available for dates that haven't
passed yet :-)
The churn dashboard starts at the beginning of June because… I had to start
somewhere. And at the time I was having to manually do a lot of data wrangling.
Eventually my automation was upgraded enough to backport to 2020. It seemed like
a fine place to stop. There's no reason I couldn't extend it back further. I
just don't need data that old for what the model is doing.
Speaking of which, what exactly is the model doing?
The model runs hundreds of thousands of simulations, using time based weights,
decays, and other "dampening" methods to predict future set lists. It's just not
reasonable to predict a 10 track set any given night. They have scores of songs.
Literally hundreds if you're being particular.
That's where The Songbook comes in.
If you filter The Songbook to just 2026, and only
include Anchors, Core Rotation, Regular Rotation, and Deep Cuts you
still end up with 100 songs:
What we can do is use probability and statistics to create a model for how
they historically write up set lists, and refine our predictions based on that.
We can incorporate a lot of attribute into this, such as venue type, if we're in
"a run" (several nights back to back), and even things like estimated set list
length and historical data. I'm not including all of that in the model yet,
it's a work in progress. Some things like learning average song/jam length are
coming in the next iteration. That greatly influences what we could expect to
hear in a given night. You wouldn't put 4 songs that tend to descend into 30+
minute jams into the same prediction for a given night in a small coffee-house
venue. You can also start to look for common segues and absolute exclusions.
Here's the context. That "90%" accuracy quote was not a lie, but also not the
whole truth. You read this far, strap in for some basic math.
Earlier I also said that we don't make 10 song predictions when we're building
predictions. We'd never get anything close to useful from that. We actually
build 30 song pools when we make predictions. Each of those has a probability
normalized from 0->1. On average given a recall@30 we "predict" 8 songs. The
model reports its nightly "expected" rate at about 20-25%, and most of the time
it's spot on. That cherry-picked screenshot above says we called 86% of the
show. But we picked 30 songs. There were only 7 songs played that night
Side note, that little greek building icon with the 1 next to it means there is 1 recoding on archive.org for that show, you could listen to it right now
When the model says 25% expected, it means it thinks about a quarter of the
songs in the prediction list, the 30-song pool, will show up in the actual
playlist. A lot of the time that turns out to be right. 20-30% of 30 is in the
6-9 song range.
But we didn't produce an artifact that had the exact number of songs in the show
that night.
I said recall@30 earlier, that's a tuning parameter of the model. If we make
the number there larger and larger our "hit rate" will increase and approach 1.0
(100%). That's because we would be producing a 100-song prediction pool.
Do you recall what I said earlier about the song book? If you filter to just the
most likely stuff this year, there they have already played 100 songs. It's a
coincidence that recall@100 would get us close to "100%" correct. But it's a
handy way to explain what this model does and DOES NOT do.
The model DOES NOT produce 90% accurate 10-song set lists
The model DOES produce pools of 30 most likely songs, of which about 25% tend to
show up. And sometimes, of those 6-9 songs that might play (it's never the top
6-9% by probability), more than half are actually played.
Here's another short recap of the last week from me.
Another shortish week as I was off monday, but still of course
a lot going on.
Aarch64 hardware fun
So, we have a bvmhost-a64 that runs 10 buildvm-a64's for koji builders.
A while back it refused to boot with a memory error. Reseating memory
got it booting again, but this week when I tried to reinstall it it failed
to boot again. At first we thought it was a bad memory stick and pulled one
to get it booting again. This took it from 512G memory to 384 (The sticks
are in pairs so it was 2 down). Since the mass rebuild for fedora 45 is
next week, I didn't want to run with fewer builders, so I had a stick
moved from a staging host. Adding that and... it didn't boot again.
Turns out on further inspection that it was the memory slot itself on
the motherboard that is bad. No memory in that slot works. :(
The vendor wanted us to ship the machine back for testing/repair/replacement.
(Normally they would replace/repair on site, but this machine was past
the time when they do that).
So, on to plan "B". I repurposed a buildhw we had to be a new bvmhost-a64
and reinstalled all the builders are we are back up and running. Of course we
will be down one builder, but that is much better than being down N buildvm's.
RHEL10 reinstalls
Made some progress on rhel10 migrations, although less than I would like.
I reinstalled all our bvmhost-x86's that run builders (and all the buildvm-x86
vm's that are on them). I hope to get a number more next week. I'm hopefull
I can do them without causing any outages, will do my best.
AWS proxy instances ssh problems
Someone wanted to debug / look at something on one of our proxies and noted
that they couldn't ssh into it, even though they were in the right groups
and should have been able to. I could not either. Login via root was still
possible, but none of our users. Nothing seemed wrong with our config, ansible
hadn't changed any in that area in quite a while. ssh config looked normal,
nothing odd in /etc/ssh/sshd_config* files. It wasn't even getting past
ssh, just saying 'ssh keys failed'. It affected all the proxies we have
that were running in aws. I did see some odd selinux denials, but setenforce 0
did not get things working.
Finally, I happened to do a ps to make sure sshd was running in the right
selinux context and found it. It was the ec2-instance-connect package.
It installs a systemd drop in for ssh that adds it's own AuthorizedKeysCommand
option, which completely overrides ours thats in config. Additionally,
removing that package causes sshd to... be disabled and stopped.
Luckily I was logged in as root and able to start/reenable it.
I filed https://bugzilla.redhat.com/show_bug.cgi?id=2498870 on this.
Another Flock to Fedora conference has come and gone, and like last year, this one was held in Prague. Unlike last year, I was not in the middle of moving across the country (again) so I was able to attend, thanks to my employer.
As always, it was great to see so many familiar faces and meet new folks face-to-face. To those of you who weren’t able to make it, you were missed. And, as always, I spent a lot of time in the hallway track talking to people, getting a sense of what everyone was working on and interested in.
Day -1
The day before the conference started, there was a sponsorship dinner. Although Bex did all the work getting the paperwork to the correct people at Microsoft, he wasn’t able to make it to Prague in time for the dinner so I was sent. I arrived on Saturday morning after a quick connection through Dublin, which gave me plenty of time to get settled in and resist taking a nap. I spent the dinner chatting with Kevin Fenzi and Jef Spaleta, and while I can’t remember all the topics, curling was definitely mentioned.
Day 0
I volunteered to help at the check-in desk the morning of the first day, which I felt went very smoothly (the new label makers were a nice addition). It was nice to help out, but it was also a great way to match names I’ve seen on Matrix to faces as folks arrived. After my shift, I got sucked into the hallway track until lunch.
After lunch and a bit more hallway track, I went to the “PR-based Gating for Fedora: Can We Make It Work?” workshop from František Lachman. There was a lot of discussion in and around the Fedora contribution workflow which I have lots of thoughts about, but I felt there was a rather widespread desire to make things better (even if the exact way we do that isn’t clear). Lots of people who were not me brought up keeping the specfiles in one repository rather than forty thousand or however many git repositories we’re up to. In any case, I’d really like a nice pull request workflow for Fedora where I can’t mess up updates, and where we can all share the tooling we build around packaging.
I spent the rest of the day in the hallway track, doing some last minute preparations for my talk on signing, and preparing for the joint Microsoft talk with Reuben and Bex. I was happy to meet some of the Red Hat folks working on cryptography and signing, and I’m hopefully somewhere down the line we can all do approximately the same thing for signing content.
I got dinner with Bex and Reuben at some place that served North Carolina style BBQ, and it was pretty good (especially with kimchi on top!).
Day 1
This was the first day of recorded presentations. I went to the usual “State of Fedora” address, followed by the Fedora Council and FESCo panels. I thought it was interesting (but sadly unsurprising) to see downward trend of contributors, and I’d be interested to see a further breakdown of who’s leaving. I have plenty of not-backed-by-hard-data ideas about why this is happening, but I do hope it leads to a stronger focus on (and acceptance of) improving the contribution experience - the general feeling in the hallways, as I mentioned earlier, makes me somewhat optimistic.
After lunch and a bit of hallway track, I went to the “Secure by Design: Aligning Fedora with the EU Cyber Resilience Act (CRA)” workshop by Jaroslav Řezník and Roman Zhukov. A good portion of it was a run down of what the CRA entailed and how the roles it describes map into Fedora. After that I spent a bit of time preparing for my talk. My talk went well, I think, except the live demo didn’t entirely work (gpg2 + gpg-agent + gnupg-pkcs11-scd is very finicky and I forgot a setup step). With that stressful event out of the way, I was able to relax a bit at the dinner party, chat with numerous folks, and fill up on the “appetizers” they brought out in vast quantities. Big props to the event organizers, the weather was great and I really appreciated the open space and variety of food options.
Day 2
It was hard to believe it was already the final day of the conference, but I think at this point I was also feeling pretty worn out. I went to Justin’s “State of the Fedora Kernel” talk, and was glad to hear that the GitLab workflow I helped build before I left wasn’t absolutely terrible. I made some last minute edits to the slides for our “Two Years In: Accelerating Microsoft Contributions to Fedora” talk (where I was happy to have Bex and Reuben do most of the talking), then helped present that talk. Afterwards I went to the “What’s new in Fedora CoreOS” talk and managed to chat with Jean-Baptiste Trystram and Joel Capitao about signing and Konflux, which we’ll hopefully get sorted out in the next couple weeks (in the staging environment, anyway). Hopefully we’ll also be able to get Fedora CoreOS images into the Azure community gallery alongside the Cloud images.
The lightning talks were all enjoyable, and I’m really impressed some folks even managed to make up slides for theirs and nothing went terribly wrong (great work everyone). There was time for a bit more hallway track, and then I went to the Contributor Recognition Program, which concluded the presentations for Flock 2026. I spent the evening catching up with old and new friends, chatting about ideas on improving various bits of Fedora infrastructure, and how to make the contributor experience better. People were already leaving for DevConf (or home) at this point, so if I didn’t get a chance to say goodbye, I’m sorry and I hope we’ll see each other next year!
Day 3
It was an uneventful trip back home, thankfully.
I’m looking forward to put all the work I’ve done on improving Fedora’s signing infrastructure through its paces, to get support for PQC done, and I have a few ideas on what to work on next. Hopefully some of them work out and don’t lead to too many people screaming at me. Flock is a great event to get excited about the next year of work and to test the waters on wild ideas, so I’m really glad I was able to make it this year.
RPM Fusion shipped Kodi 22-beta1 for Fedora 44. This is the version
with PR adding HDR support under Wayland merged.
It's a bit weird seing a beta version submitted as an update to stable branch, but hey, it works.
Thanks Leigh!
It works OK under GNOME session with HDR enabled. The UI elements are bit oversaturated
when playing High Dynamic Content, but the videos themselves are pretty. At last. This is
the year of HDR on Linux Desktop.
If only GeForce Now would catch up with the times…
The second quarter of 2026 is over, and so in this post we’d like to highlight the top Fedora Quality contributors who helped us maintain the quality bar for Fedora during this time period. Fedora wouldn’t be a high-quality distribution without its community. Every single person who helped us detect and resolve issues, or verify that things work as expected, deserves our gratitude, thank you!
If you haven’t participated yet in testing Fedora, perhaps you’d like to give it a try? We gladly welcome everyone. Please look at our Fedora Quality homepage.
Testing proposed updates
When software packages are updated in Fedora (bringing bug fixes and new features), they are not released to end users immediately. They first go to the updates-testing repository, where they undergo automated testing, and also await manual feedback from human testers. This feedback can be provided through Bodhi, either by using its web interface or CLI tools, see instructions. Alerting package maintainers by posting a negative feedback with a problem description can stop the update from reaching general audience and causing issues to all our users. Testing proposed updates is a simple, yet vital process for keeping Fedora releases of high quality during their whole lifecycle. It is used both for already stable and in-development Fedora releases.
…and also 358 other testers who commented on less than 10 updates each, but 750 comments combined!
1 If a person provides multiple comments to a single update, it is considered as a single comment. Karma value is not taken into account.
Test days participation
Test Days are events which are partly focused on testing Changes planned for an upcoming Fedora release, but they also regularly test important areas of the Fedora distribution, like upgrades, internationalization, graphical drivers, desktop environments, kernel updates, and others. The upcoming and past events can be seen in our Testdays app.
Test period: Q2 2026 (2026-04-01 – 2026-06-30) Contributors: 25 Test cases executed: 76
This post announces "simple gals", or simpleGals stylized. This is my first
new semi-serious open source project in a long time. Like
bitmath I had an itch I needed to
scratch. And that itch was the apparent lack of a modern day "simple HTML image
gallery generator".
Back in my day, on Mac the Photos application had this nifty feature. You
could export a gallery to a simple HTML bundle with forward/backward nagivation.
It looked a lot like they used the DocBook XSL stylesheets to generate a simple
thing that worked really well. Speaking of which, I still have an example of
thing I"m talking about.
The Grand Library is one of the first big planned on graph-paper projects I
made in Minecraft, back when I was in college and it was still IN ALPHAv1.1.2_01. According to the wiki, this screenshot must have been taken between
the ass-end of
September and October
30th, 2010.
You can see the rest of that gallery
here with (most of) the full
build from beginning to end.
I think I had a screen recording, or screenshots of, a giant library burning
(after we backed up the world files). It brought the server (probably my old
macbook) to its knees. It was rough, buddy. But that's what we did back then: we
mined, crafted, and burned shit down/blew shit up. Not much has changed really.
That Apple generated HTML image gallery is the inspiration for simpleGals. It's
so stupid simple. Rows. Columns. Pagination. Click to view full size. It's
perfection.
simpleGals is trying to be a very simple command-line driven static HTML image
gallery generating tool. simpleGals just like to have fun, it doesn't want you
getting bogged down with all the tedious overhead associated with fancy gals,
running software that has to get patched, or paying another subscription.
simpleGals ain't like that.
simpleGals isn't for album management. You feed simpleGals directories of images
and in return you get some simple HTML files with thumbnails.
simpleGals inserts some simple javascript for quality of life enhancements. But
exactly 0 user-facing functionality requires javascript. The functionality
degrades gracefully to a simple point and click adventure, just like the old
days.
simpleGals has a full TUI interface for configuring projects and modifying
properties. The sgui tui can rebuild the gallery, just as well as the batch
simpleGals command. There are progress bars, because I was feeling fancy.
Also, you get actual image-previews IN THE CONSOLE when you're setting
captions/alt text, or toggling individual "include in gallery" options.
For over a year now, Log Detective has provided an analysis of failed package
builds in Copr.
Relatively recently, we have also integrated our service with Packit.
Now, you can use our log summarization algorithm with your own
agent, using our new MCP server.
Rather than relying on a remote service, the logs are all processed locally.
Installation
Installing Log Detective MCP server is as simple as pip install logdetective-mcp.
In order for your agent to have access, you need to follow relevant guidelines.
For example, adding the server to Claude Code:
claude mcp add logdetective -- logdetective-mcp
For Pi, you would first need to install appropriate MCP extension,
such as pi-mcp-adapter.
Using Log Detective MCP
After installation, the tool is ready for use.
Testing with Claude Code, on a simple example of failed build from Copr,
has revealed savings in the token budget, compared to the naive approach
of the agent reading the log file directly.
Analysis without Log Detective MCP:
Analysis with Log Detective MCP:
The agent response is also substantially faster.
How does the extract_log_snippets tool work
The MCP server provides a single tool, extract_log_snippets, derived
from tools used by our production agent.
Unlike our service, only general heuristics are supported at this time.
That being said, for many use cases, they are sufficient.
Just like our agent, the tool uses an updated fork of Drain3,
which I have published on PyPI.org and maintain.
The extract_log_snippets tool exposes several parameters to your agent,
controlling granularity and removing irrelevant snippets.
Parameter
Type
Default
Description
max_clusters
int
8
Maximum number of snippets to extract.
max_snippet_len
int
2000
Maximum character length per snippet.
skip_patterns
dict[str, str]
null
Map of names to regex patterns. Matching chunks are excluded before clustering.
The default values were chosen to minimize impact of the tool on your token
budget, while still extracting enough useful data on the first attempt
in most tested scenarios.
When used in skills, it is recommended to highlight that the tool provides
more benefit when utilized with files with line count over 200.
It is also mostly useful for working with one message per line, although
the tool does have a simple heuristic for extracting multi-line messages.
The Fedora Package Review Process is clunky, archaic,
and not on par with what we expect when contributing to Open Source projects in
this century. We all know that, and we all want it to improve. That being said,
we need to realize what is currently our main bottleneck. Even though the
process is not friendly to new contributors, they are doing just fine - at all
times, we have hundreds of new packages in the queue. Our biggest
problem is our inability to effectively review them.
I don’t think we talk about this problem enough. That’s why it felt so
validating to hear Miro Hrončok voice my exact thoughts during the
Flock to Fedora 2026 keynote.
In this blog post, I am going to elaborate on the ideas that we (mostly Miro)
came up with, shooting shit in the hallway after the session.
Proposing new packages through PRs
This is an obvious one, we talked about the same idea with
Zbigniew Jędrzejewski-Szmek at Flock to Fedora 2025. It
is a necessary prerequisite for any potential improvements, which will allow us
to have a workflow that contributors are familiar with, inline code comments,
CI/CD, and other things that are not possible in Bugzilla.
Proposing new packages through PRs would be trivial to implement if we
had all Fedora packages in a monorepo. Which we don’t, and we probably
don’t want to have. And even if we wanted to have, it would require
massive changes throughout the ecosystem.
As a workaround, we discussed having an intermediate repository on the
forge.fedoraproject.org into which we would only propose new
packages. It would have Packit CI enabled, and therefore every
proposed package would automatically get a scratch build and a test suite run on
top of it. Currently
supported tests are rpmlint, rpminspect, and license-validate.
We know that adding new tests is easy, as I am currently working on support for
fedora-review.
Of course, a final approval from a fellow package maintainer would still be
needed. Once accepted, we would merge the PR and automatically create a new
DistGit repository and import the package. Then we would delete all data from
the intermediate repository to keep it clean.
Bulk review
The review queue is and always has been in hundreds. Many of the packages are
dependencies for something else, and people have no motivation to review them
separately. And even if they do, it’s not always easy to test them on their
own. This currently leads to accepting broken packages that nobody tested or
ignoring the tickets completely.
We discussed the possibility of proposing multiple packages within one PR. They
could be reviewed, tested, and accepted all at once.
For such PRs, we could automatically create a new project in Copr and build the
packages in the order they were committed. We could nicely use
Copr’s build batches feature here. If multiple packages were
added in one commit, they could be built in parallel. If the contributor decides
to force-push into their PR, we would wipe the Copr project and start over.
Auto import into DistGit
There is no reason why the contributor would have to manually run
We can request all the DistGit repositories and branches for them. And once they
are created, we can automatically import the packages. There are some open
questions though. How can the contributor signalize what branches they want?
Should we use the git history from the PR? Can we use Forgejo actions to trigger
the requests and imports?
Proposal vs prototype
I realize this is not a formal proposal but merely a blog post on my personal
website. That was an intentional decision. We’ve been discussing and
bike-shedding this topic for years, and yet we don’t have much to show for it. I
am writing this article mainly not to forget the ideas we’ve had, and even
though I am interested in your thoughts, this is not an RFC. I already started
implementing a prototype, and soon I’ll record a demo for you. Then, I’ll start
bothering you and asking for feedback.
In my opinion, it doesn’t have to be perfect. We just need to kick this off,
implement something small that works, and improve it as time goes.
Maybe I should also say that I am not aiming to replace the current
Package Review Process. My goal is to provide an
alternative version of this process and allow contributors to choose which one
they want to follow. Then, someday in the future, if the alternative turns out
to be popular, possibly deprecating the old review process.
At the beginning, I struggled to find reasonable use cases for this tool.
I maintain software, which involves a lot more communication and coordination than actually writing code.
When people ask me what I do, I often half-jokingly reply that I read and write a lot of emails.
How can AI boost my productivity when I spend 80% of my time essentially talking to people?
Where is the fun in replacing the remaining 20% of actually crafting code with more talking, this time to half-competent robots?
In time, I found ways to use AI that felt productive.
And, ever so hypocritically, not only at work.
But at what cost?
I am supporting an industry that regularly harms open source projects such as Fedora, helps destroy the planet and uses stolen data.
Moreover, I’ve become reliant on a proprietary tool.
Is my AI-boosted contribution to Fedora worth it?
Despite my moral dilemma, I still love my job.
I am a long-standing, well-known Fedora contributor, working for the most part on whatever I feel is needed, earning a competitive salary.
In theory, I could go look for another job where I would not be motivated to do this, but I wouldn’t be able to keep doing the thing I love.
I try to make the best out of this situation and, despite my initial distaste, use the tool to improve the project.
So at the end of the day, I close my eyes and think of Fedora1.
However, the implications of embracing AI are not just impacting me.
The nature of my work means I’ve made hundreds (thousands?) of small open source contributions here and there.
And sometimes, when I use AI to deliver those, it kinda feels like bringing a chunk of meat to a vegan BBQ.
The people on the receiving end of my contribution for the most part don’t care about my job sustainability or IBM shareholders, nor should they.
Once, I used AI to contribute to a Fedora packaging project.
It was reluctantly reviewed by another long-standing, well-known Fedora contributor (who happens not to be employed by Red Hat and is not well-compensated for this work).
When talking to them, I realized that they were uncomfortable reviewing such a change.
I made them uncomfortable by choosing to use AI for this.
My employer made me uncomfortable; I passed it on to a volunteer.
What an outstanding open source citizen.
I appreciate the irony of this; and yet, I am no slop generator.
I understand what I submit and I put my name on it.
I disclose the usage for transparency, because it matters.
I don’t just drop a vibecoded patch on an open source project.
If you have an AI policy, I read it and respect it.
So it pains me deeply when our carefully considered contributions are outright branded AI slop or LLM hallucinations, and the person bringing them is evaluated solely on the basis of the tool they used.
Especially when such judgment is made by people I respect2.
No, I am not a tool. Please don’t treat me as such.
PS On a lighter note, here are some examples of AI usage that somehow eliminate this problem for me:
Debugging a problem — in our team we’ve been very successful in showing a failing test to Claude and telling it that it started failing with Python 3.15. While burning thousands of tokens and wasting gallons of drinking water it can usually successfully determine what caused the failure. We were able to determine this ourselves in the past, but this actually boosted our productivity. We can then report the problem to upstream after we have verified the find.
My own/my team’s semi-internal tooling —3 the omnipresent bunch of random scripts I am not proud of and which would desperately need a rewrite but ain’t nobody got time for that. Just slop ‘em. If it works, it works. If it doesn’t, roll-back. Nobody needs to see this code anyway. Excellent for AI — I am still kinda killing the planet but at least I don’t shove it in your face.
Reporting to management — somehow people keep asking me what I did. There’s no dilemma in providing AI-generated reports to the same people who asked me to use AI. If nothing else, it demonstrates how progressive I am with it.
Reviews for me — when I don’t use AI to generate code, but rather ask it to review my design and implementation, nobody is forced to deal with my AI usage. For example, I wrote this blogpost myself, then asked AI for feedback on typos, grammar, tone, voice, argument, rhetoric, structure, flow…4
And perhaps even more so, my mortgage and the food on my table. ↩
And precisely because of that I choose to not link those cases here. This is not about naming and shaming. ↩
This m-dash was copy-pasted from websearch results by a human. ↩
If nothing else, at least the model pretends it appreciates my sarcasm. ↩
A reminder that I am no longer here, but am instead here. The new RSS feed is here. If you're still reading this for some reason other than being on Dreamwidth, please update your feed.
"Today's the fourth of july.
Another june has gone by."
(appologies to Amiee Mann).
Here's another short recap of the last week from me.
I was off Thursday, and Friday was a holiday, and I'm off next monday too,
so this was a short week.
aarch64 builders and vmhosts reinstalls
I spend a bit of time reinstalling our aarch64 bvmhosts. These are the
machines that run all our buildvm-a64 instances. You would think this would
be a trivial task, but of course not.
When we got these machines as part of the datacenter move last year,
we couldn't get them to pxe boot from their 25G network. So, we ended
up patching some 1G connections to them to provision them. Then those
links were removed. So, I needed to fix the issue this time.
Turned out it was just some settings in the network card eeprom/settings.
To adjust it, I had to build a kernel module, load that, then poke
at the settings with a tool. Quite a pain, but luckily only a one
time thing.
After that, they pxe booted fine and were easy to reprovison with rhel10.
Except, then I hit the next thing: One of them had a bad memory stick
in it. We had hit this before, but after reseating all the memory
it came up ok, but that memory just decided to croak this time.
So, dc operations folks did a bunch of testing and isolated the bad
memory. Should be on the way in to get a replacement now. Until
the replacement arrives that machine is down memory, so a few buildvm's
on it are shutdown. Shouldn't matter too much.
Staging openshift workers network
Last week we moved a number of servers to balance power in racks.
That went fine, but networking folks noticed that 3 of the machines
were not properly using 802.3ad/lacp. That is, they were only connected
on one interface. These machines were our staging openshift workers.
It took me quite a lot of poking around to see what happened and how to fix it.
Openshift has a lot of ways it configures network and it was not clear at all to
me the flow. I did finally figure it out though: I had installed them with
net.ifnames=0 set. This meant they had eth2 and eth3 interfaces that were the
active ones. After the install, they booted without that and so the interface
names changed. The new ones didn't have any config, so it just picked the
first one and ran it's ovh setup on. So, I had to go in and setup NetworkManager
to know about the new interface names so it would bond them, then the openshift
setup script would just take that bond device and setup on it.
This is a report created by CLE Team, which is a team containing community members working in various Fedora groups for example Infrastructure, Release Engineering, Quality etc. This team is also moving forward some initiatives inside Fedora project.
Week: 29 June – 3 July 2026
Fedora Infrastructure
This team is taking care of day to day business regarding Fedora Infrastructure. It’s responsible for services running in Fedora infrastructure. Ticket tracker
This team is taking care of day to day business regarding CentOS Infrastructure and CentOS Stream Infrastructure. It’s responsible for services running in CentOS Infrastructure and CentOS Stream. CentOS ticket tracker CentOS Stream ticket tracker
This team is taking care of day to day business regarding Fedora releases. It’s responsible for releases, retirement process of packages and package builds. Ticket tracker
Continued investigation into building a Fedora container base image using Konflux.
Continued work on remaining Pagure -> Forgejo migrations.
F45 release cycle is set to begin soon, starting with Mass Rebuild in the middle of July. This will require some prep work next week.
RISC-V
This is the summary of the work done regarding the RISC-V architecture in Fedora.
Discussion with Scaleway (a cloud vendor in France) for potential Fedora Koji builders in their Paris datacenter. To be coordinated via RISE.
Hardware
Coordinated shipping another “K3” hardware to DavidA (one of the Fedora RISC-V maintainers). This will be used as another RISC-V Koji builder. Sponsored by CLE.
Milk-V Titan hardware is now available to buy. A handful of machines are being shipped to a couple of RISC-V engineers, including for Fedora use.
Community work
Fedora Omni kernels for Muse Pi Pro hardware discussion with Trevor from Baylibre and Jason (Fedora RISC-V kernel)
Marcin (hrw) Juszkiewicz continues to chip away at the Fedora RISC-V tracker
Fedora Omni kernel work continues, with support for Muse Pi Pro, K3, and more: Jason Montleon and Jennifer Berringer
Other:
Discussions on ‘fedora-devel’: “How can we improve the Changes Process?” thread
A lot of internal discussion about 2FA for packagers
Several internal and upstreams meetings
AI
This is the summary of the work done regarding AI in Fedora.
Aurelien Bompard improved the This Week in Fedora script to include the CLE status reports
QE
This team is taking care of quality of Fedora. Maintaining CI, organizing test days and keeping an eye on overall quality of Fedora releases.
Lots of PTO: psklenar on extended PTO, kparal and adamwill each took some post-travel PTO days. Also post-event travel, bureaucracy (trip and expense reports) and decompression cut into work time for most
Compose-critical package script now in MVP state – see pull request, it works and does useful stuff but needs more refinement
Version 8.6.0alpha1 has been released. It's still in development and will soon enter the stabilization phase for the developers and the test phase for the users (see the schedule).
The RPMs of this upcoming new version of PHP 8.6, are available in remi repository for Fedora ≥ 43 and Enterprise Linux ≥ 8 (RHEL, CentOS, Alma, Rocky...) in a fresh new Software Collection (php86) allowing its installation beside the system version.
As I (still) strongly believe in SCL's potential to provide a simple way to allow installation of various versions simultaneously, and as I think it is useful to offer this feature to allow developers to test their applications, to allow sysadmin to prepare a migration or simply to use this version for some specific application, I decide to create this new SCL.
I also plan to propose this new version as a Fedora 46 change (as F45 should be released a few weeks before PHP 8.6.0).
Installation :
yum install php86
⚠️ To be noticed:
the SCL is independent from the system and doesn't alter it
this SCL is available in remi-safe repository (or remi for Fedora)
installation is under the /opt/remi/php86 tree, configuration under the /etc/opt/remi/php86 tree
the FPM service (php86-php-fpm) is available, listening on /var/opt/remi/php86/run/php-fpm/www.sock
the php86 command gives simple access to this new version, however, the module or scl command is still the recommended way.
for now, the collection provides 8.6.0-alpha1, and alpha/beta/RC versions will be released in the next weeks
some of the PECL extensions are already available, see the extensions status page
tracking issue#342 can be used to follow the work in progress on RPMS of PHP and extensions
the php86-syspaths package allows to use it as the system's default version
ℹ️ Also, read other entries about SCL especially the description of My PHP workstation.
GNOME developers have long used G_GNUC_CONST, which expands to __attribute__((const)), to annotate GObject _get_type() functions, despite knowing that it is incorrect to do so. const functions by definition have no side effects, but _get_type() functions actually have a side effect the first time the function is called: they initialize the type. Why apply an incorrect annotation to these functions? Because it makes the code faster.
Although this was long known to be incorrect, it worked fine in practice… until now. Regrettably, Sam James has discovered that GCC 16 may optimize away the type initialization, resulting in crashes. This is our fault for providing the compiler with wrong information about our code, so it’s time to audit your use of const attributes to remove them from _get_type() functions. Most GNOME programs use these attributes only for _get_type() functions, but if you use it in more places, then check to make sure those functions are actually const, as defined by the GCC documentation.
Sadly, there is no suitable replacement attribute for _get_type() functions. Two decades ago, Behdad requested a new idempotent attribute for expressing the desired semantics, but nobody has implemented it.
Time for a recap of the last week in my #fedora infra space
(here in longer form).
Overall this week was a bunch of catch up from being away at flock,
along with recovering from Jetlag.
RHEL10 migrations
I scheduled an outage on thursday for the last of the external
colo virthosts to get a RHEL10 reinstall. I had tried to do it
in the last outage, but I wasn't able to do it in the normal
way that preserved all the guests data. This time I managed
to get it done, but it took longer than I would have liked and
I hit a number of fun issues:
Using a remote console I can't hold down shift to get a grub
menu, so I had to hit escape at the right time.
rdp for Fedora is not great still. gnome-connections is still
the winner, but even it has quirks.
The /boot/efi partition still did not want to let me reformat
it as part of the install. I thought it was because there
was a spare in the raid1 for it, but I grew it to use that
spare and it still didn't help. So, I ended up just deleting
it and recreating it.
Finally all reinstalled, reprovisioned and all the guests
brought back up.
There's still a number of hosts to move, and we are down
to trickier ones, but we will look at another outage probibly
week after next to do more.
2fa in Fedora
Fesco decided to require all provenpackagers to enroll a 2fa
token. There's a lot of talk about expanding that to packagers,
or even everyone.
I thought I would share some info around this for interested
folks who may not have seen it in all the various threads
or tickets:
The Fedora account system frontend (noggin) supports enrolling
TOTP tokens. Once you enroll one you must use it to login to
the account system, to get a kerberos ticket, and to login
to any web application with your fedora account.
You can (and should!) enroll more than one token. As far as
I know, there's no limit to number you can add. You can also
disable or delete tokens, so long as you still have one
token enrolled. ie, you can never delete the last one.
Any enrolled, non deactivated token will work to authenticate
you. So, it's good to have at least one saved off to a safe
place in case you loose access to your primary token.
If you somehow loose access to all your tokens, the recovery
process is to mail admin@fedoraproject.org and you will be asked
to prove you are you. This may be a gpg signed email (with the
key associated with your account), using your ssh key associated
with the account, or other means.
So, please make sure you have a backup token to avoid that. :)
TOTP is pretty common and has been around a long time. Lots
of software is capable of storing your secret and displaying
tokens.
s390x builds backup and koji session bug
On friday morning our koji s390x builders were getting swamped.
It was the same story with a lot of large builds taking up builders
so other things couldn't get in. Or so I thought at first, but on
digging there was another problem. It was caused by a koji bug
(already fixed upstream, but not released yet). This caused
tasks to get freed and just sit there and not progress.
I have applied the patch and updated our hubs, and then went
through and reassigned all the tasks I could see that were still
having problems. Let me know if you see any I missed.
I also pulled in 2 more builders to the general build pool
One I had set to only do kernel builds a while back when we
were trying to get security updates out fast.
One was a compose host, but I think we can be fine with one
less compose host.
So adding those two helped process the backlog too.
I've also filed another request for more resources, but so far
it hasn't really gone anywhere. ;(
Some PTO next week
Next week, I am going to be taking thursday off and friday is a holiday
in the US, and I am taking off the following monday too.
Of course I'll still be around, but possibly doing other things. :)
How to migrate Fedora OS from one system to another, across network or (better) a Thunderbolt connection, without cloning the whole disk contents, saving SSD life.
Background
When migrating a Linux installation from a source drive to a target drive of a different size, traditional block-by-block tools like dd don’t allow to migrate to a smaller drive, and also waste SSD life by writing unused blocks. This guide describes a simple approach in which different disk sizes can be used, and the process is performed over network (or Thunderbolt), so that it’s not necessary to place two physical disks in the same device. The target system is exactly the same as the original, with all partition and filesystem UUIDs staying the same, which means no post-migration OS configuration is necessary. The time and SSD wear is minimized by pre-shrinking partitions and skipping unallocated disk space entirely. The default Fedora Workstation disk layout is supported, including LUKS encryption of the system partition.
This guide expects the following disk layout:
/dev/nvme0n1p1 — ESP (most often FAT)
/dev/nvme0n1p2 — Boot partition (most often Ext4)
/dev/nvme0n1p3 — System partition (most often Btrfs, optionally encrypted using LUKS)
For simplicity, this will not try to skip copying all unused blocks, just most of them. The first two partitions will be cloned in raw mode. The third partition will be shrunk first (thus saving lots of blocks from being copied, and also supporting smaller target drives), and then cloned in raw mode.
Migration steps
Shrink the system partition on the source system
On the source system:
Delete all necessary data, prune cash dirs, empty the trash, etc.
Make sure that filesystem consistency of your System partition is OK: sudo btrfs scrub start -B / This will take a couple of minutes, but you can check the progress with sudo btrfs scrub status /, if needed.
Boot to a Fedora Workstation Live system from a USB drive.
Run Gparted. In it, unlock the system partition, if encrypted. Then shrink the partition to a reasonable degree. For example, if the partition has 950 GB (from a 1 TB disk), but only 300 GB is used, you can shrink it e.g. to 350 GB. That still leaves enough free space for regular usage if you had to boot it for any reason, and saves 600 GB from being copied needlessly. This operation might take some time, because any data blocks currently present after the new size limit will need to be moved (therefore don’t be too aggressive in setting the limit). If your partition was encrypted, make sure that both the LUKS encryption container and the filesystem inside it correctly show up as resized.
Unmount all partitions (if any), lock the encrypted partition (if applicable) and close GParted.
Erase the target system
On the target system:
Ensure that this is really the system you want to completely erase (and replace with the OS from the source system).
Ensure that the disk size is sufficient to fit all partitions from the source system (now that the system partition on the source system has been shrunk).
Boot to a Fedora Workstation Live system from a USB drive.
Unmount all partitions (if any). You can use e.g. GNOME Disks for this.
Erase the whole drive (make sure you’re using the correct system): sudo wipefs -a /dev/nvme0n1
Discard all blocks on your drive (better for your SSD longevity): sudo blkdiscard -v /dev/nvme0n1
Configure power saving
On both systems:
Disable automatic suspend. You don’t want that to happen when doing disk operations. gsettings set org.gnome.settings-daemon.plugins.power sleep-inactive-ac-type nothing gsettings set org.gnome.settings-daemon.plugins.power sleep-inactive-battery-type nothing
Disable screen blanking and locking. You probably want to see the screen output at all times. gsettings set org.gnome.desktop.session idle-delay 0 As a bonus, you can also disable screen dimming: gsettings set org.gnome.settings-daemon.plugins.power idle-dim false
Establish an Ethernet/Thunderbolt network link
If you have both systems connected to the network and intend to use it, skip the Thunderbolt setup section below. Instead figure out the IP addresses of both systems (using the ip address command) and go to the Connectivity test.
Thunderbolt setup
If you want something faster than a regular network, have Thunderbolt ports on both systems and a fast USB-C cable ready, you can use that instead. With Thunderbolt, you can transfer data with 10 Gb/s speeds or more, compared to the common 1 Gb/s of a standard Ethernet.
On both laptops, after connecting them through a Thunderbolt cable, locate the network interface name: ip link Look for an interface like thunderbolt0.
Assign static IP addresses to them:
Source system: bash sudo ip addr add 192.168.5.1/24 dev <interface_name> sudo ip link set <interface_name> up
Target system: bash sudo ip addr add 192.168.5.2/24 dev <interface_name> sudo ip link set <interface_name> up
Connectivity test
Let’s use a well-named variable for both numbers, so that we don’t mix them up later. On both systems, run:
You should see both systems pinging the other system correctly.
If you want to test your connection speed (e.g. to pick the best USB cable), you can use iperf3.
On the target system, run the server: iperf3 --server
On the source system, run the client: iperf3 --client $TARGET_IP (you can add --format G to see the speed in bytes instead of bits)
Replicate partition table from source to target
This will make an exact copy of the source system partition table (including partition UUIDs) on the target system. Then we will adjust it to the different disk size.
On target system, start listening for data and save it:
nc -l -p 2000 > table.txt
On source system, dump the partition table and send it over:
Now that the target system is a complete clone of the source system, you can expand the System partition to fully utilize the remaining disk space. In Gparted, unlock the system partition, if encrypted. Then enlarge it according to your preferences. If your partition was encrypted, make sure that both the LUKS encryption container and the filesystem inside it correctly show up as resized.
Reboot the target system
You can now reboot the target system, and you should see your OS and data exactly the same as on your source system.
Check the filesystem consistency of your System partition:
sudo btrfs scrub start-B /
This will take a couple of minutes, but you can check the progress with sudo btrfs scrub status /, if needed.
If there are no problems detected, the process is now complete.
Boot problems
In case the target system has a very different hardware from the source system (e.g. a different brand of a graphics card), the drivers might be missing from the current kernel initramfs and you can see a black screen or kernel errors. In that case, reboot the system again, press F8 repeatedly during boot to get into the GRUB bootloader menu, and boot the rescue Fedora option, instead of the default one. That should hopefully boot using the generic image (which should contain all known drivers), and then you can regenerate all the kernel images using your current hardware setup with: sudo dracut --regenerate-all --force
Mentions of other cloning approaches
Using dd This works fine when cloning to a larger disk (if you fix the partition table afterwards), but unused blocks are written needlessly (wearing down SSD), and migrating to a smaller drive is problematic.
Native Btrfs streams using btrfs send and btrfs receive This perfectly copies only used blocks of the main partition, but it only submits a single subvolume. Which means there’s some extra work needed to make sure exactly the same subvolumes are replicated from source to target. Also, this works above the LUKS encryption, which also needs to be created manually on the target (while keeping IDs, etc).
Using Clonezilla Clonezilla will copy LUKS partitions as raw data, because it can’t see inside. Furthermore, it doesn’t support cloning to a smaller drive by default (there are some tweaks in Expert Mode, but you need to repair the GPT backup table manually anyway).
Sparse-copying the whole disk You can clone and restore the whole disk image with sparse blocks support, as seen in this guide. With a little tweaking, this approach could potentially be used even for my use case. One would need to make sure all the unallocated blocks are freed and really contain zeroes (which means running fstrim or blkdiscard and testing if it zeroed it out), and the partitions would need to be shrunk first in case of migrating to a smaller drive. The GPT backup header would need to be fixed (the same way as in the main article). So this might be a viable alternative approach for those who know how to tweak the steps.
Ampere Altra Q80-30 processor (80 cores at 3.0GHz)
RAM
128 GB (8x 16GBHMA82GR7CJR8N-XN)
GPU
AMD Radeon RX6700XT
NVME
Lexar LM9702TB ADATASX8200 Pro 1TB
Motherboard
ASRock Rack ALTRAD8UD-1L2T
PSU
MSIMPGA850G (850W)
Case
Endorfy 700 Air
USB3
no-name USB 3.2/10Gbps controller (PCIe x4)
To be fair, I should mention that this is a server motherboard, not a desktop
one, and Altra systems were never meant to be desktops (despite companies
selling them as such). Naturally, the list of tested/approved devices (Qualified
Vendor List (QVL for TLA fans)) is quite short and for Ampere Altra systems, it
does not contain AMD Radeon GPU cards. They can be made to work, but this often
requires additional effort.
The extra USB 3.2 controller allowed me to have more USB devices than the
motherboard alone supported, and gave me some 10Gbps ports for connecting
external NVMe drives.
The whole system was running just fine* under Fedora 42–44.
The first issue
Have you noticed the small “*” at the end of the previous paragraph? The system
I used was not quite Fedora — I had to use my own, self-built kernel.
You see, the PCI Express controller in the Ampere Altra has some issues. Let me
quote the description of
the Ampere Altra erratum 82288 patches:
Per Altra family erratum, PCIE_65 may cause invalid addresses to be generated
on PCIe mmio writes, impacting certain device types, notably AMD GPUs, and
thus the Altra family is not generally compatible with those device types.
And longer description from patch itself:
PCIe device drivers may map MMIO space as Normal, non-cacheable memory
attribute (e.g. Linux kernel drivers mapping MMIO using ioremap_wc). This may
be for the purpose of enabling write combining or unaligned accesses. This can
result in data corruption on the PCIe interface’s outbound MMIO writes due to
issues with the write-combining operation.
The workaround modifies software that maps PCIe MMIO space as Normal,
non-cacheable memory (e.g. ioremap_wc) to instead Device, non-gathering memory
(e.g. ioremap). And all memory operations on PCIe MMIO space must be strictly aligned.
So, to have a working Linux system, I had to rebuild the kernel on every package
update. Which usually meant “weekly”. Each Monday or Tuesday, I would update
the local copy of the Fedora kernel package repository and build it using my own
versioning scheme, like “7.0.2-200.fc44.pcie65.6”. The “pcie65” part reminded me
which patches I had applied, and the “6” was a counter for the patch rebases.
I cloned the repository from GitHub and then rebased patches, adapting them
whenever they needed work. The side effect was that I often used a newer kernel
than the official Fedora release — there is a “stabilisation” branch in the
Fedora kernel package repo where the soon-to-be-pushed version is present. So,
when Fedora had 6.19.y kernel, I had 7.0.z one.
So many cores, not enough speed
As I wrote in my previous post,
having eighty CPU cores does not mean that the system is a good, fast desktop machine.
AMDGPU started failing
As I mentioned above, to get my AMD Radeon RX6700XT running properly I had to
alter kernel with the out-of-tree patches. It worked, I could play some games,
watch videos with hardware-assisted video decode acceleration.
Until one day, around the Linux 7.0 release, when it started to fail. Running a
game ended with:
kernel: amdgpu 0000:03:00.0: Fence fallback timer expired on ring vcn_dec_0
kernel: amdgpu 0000:03:00.0: Fence fallback timer expired on ring vcn_dec_0
kernel: amdgpu 0000:03:00.0: Fence fallback timer expired on ring vcn_dec_0
Over and over again. Watching YouTube videos became impossible due to 720 out of
750 frames being dropped, etc.
Normally I would start to bisect the kernel to find out where the problem is.
But I was running a tainted kernel due to PCIE65 patches so who knew where the
problem actually was…
Let’s get Nvidia
I bought an Nvidia RTX 2060 graphics card and put it in place of the AMD Radeon.
It turned out that if I wanted to use it with the nouveau kernel driver I
still needed PCIE65 patches applied…
So I tried default Fedora kernel with Nvidia binary driver. And it worked fine.
Video decoding was accelerated, some games under Wine worked as well.
But then I started FreeCAD. And OrcaSlicer. And in both cases I got crash and exit…
It turned out that there was no org.freedesktop.Platform.GL.nvidia in Flatpak
repositories for AArch64. And I used both of those tools quite often.
Powering up the old x86-64…
At that point, I gave up. And booted my x86-64 system, which had been powered
off all that time. There were a lot of cables to move, some new ones to arrange,
and now I have both “wooster” (Ampere Altra) and “puchatek” (Ryzen 5 3600)
systems running under my desk.
Moving from 80 cores to 6 cores (12 threads) was a weird experience. A much
smaller number, yet things work fine. I can load all threads and the music still
plays. All games from my Steam library are playable. A working FreeCAD allows me
to finish designing cases for my home projects and I can 3D print prototypes
straight from OrcaSlicer.
The “wooster” system stays powered on, churning through RISC-V package builds.
It may be weak in single-thread, but it flies when it comes to multi-core load.
Conclusion
As for the Ampere Altra, I am not planning to repeat this experiment. Another
AArch64 desktop attempt would require a completely new hardware platform. And I
have no plans to spend over twenty thousand PLN to buy an Nvidia DGX Spark system.
This is a report created by CLE Team, which is a team containing community members working in various Fedora groups for example Infrastructure, Release Engineering, Quality etc. This team is also moving forward some initiatives inside Fedora project.
Week: 22 – 26 June 2026
Fedora Infrastructure
This team is taking care of day to day business regarding Fedora Infrastructure. It’s responsible for services running in Fedora infrastructure. Ticket tracker
This team is taking care of day to day business regarding CentOS Infrastructure and CentOS Stream Infrastructure. It’s responsible for services running in CentOS Infrastructure and CentOS Stream. CentOS ticket tracker CentOS Stream ticket tracker
Attended/interacted with some Folks contributors (remotely attending and chat in matrix rooms)
Created other tickets for .stg. stream el10 staging signing service (network ports for fedora-messaging stg rabbitmq hosts and two new service principals) – https://redhat.atlassian.net/browse/CS-3414
Prepared staging host for centos-stream signing (https://redhat.atlassian.net/browse/CS-3414) but now blocked with a fedora infra staging issue (rabbitmq) so tried the whole day to debug but need someone from Fedora infra side to solve the issue there
Riscv64 discussion about a new p550 hardware firmware upgrade
Tested and validated that RH network team opened needed port for rabbitmq.stg.fedoraproject.org
RISC-V
This is the summary of the work done regarding the RISC-V architecture in Fedora.
F45 rebuild started — we’re trying to first focus on language toolchains — need to refer to Miro’s lightning talk from Flock on how they handled Python bootstrap
F44 is being kept up2date (there were some big updates, including GCC)
Kevin did the legwork to move away from old dist-git on fedora.riscv.rocks to forge.fp.o
Another K3 builder in Fedora Koji — another member added. (This might sound like a tame update, but all compute power is helpful / important to keep the build momentum :-))
Discussed some details of riscv64 in primary Koji ticket
This team is taking care of quality of Fedora. Maintaining CI, organizing test days and keeping an eye on overall quality of Fedora releases.
Flock & DevConf attendance, lruzicka gave a talk on openQA test investigation, adamwill gave a lightning talk with cle about Fedora CI improvements, several of us were involved in a workshop/roundtable about the viability/desirability of moving all testing to dist-git PRs, lots of productive side conversations etc., many about AI – trip reports / blog posts coming
Lots of work to enable testing of the huge OpenSSL 4 update for Rawhide, investigate a significant bug that showed up, and eventually bypass the test failures for that bug as it’s proving not to be possible to resolve in a reasonable time (the update needed to get merged)
Continued tech debt / enhancement work on blockerbugs, testdays-web and issuebot
Forgejo
This team is working on introduction of https://forge.fedoraproject.org to Fedora and migration of repositories from pagure.io.
PTOs & travel
On Zabbix staging, now have a working template to monitor the Forgejo runnerhost VM and the runners themselves
Continued work on Private Issues (private comments refactoring)
UX
This team is working on improving User experience. Providing artwork, user experience, usability, and general design services to the Fedora project
Updates to translations of Fedora Documentation are again available. As announced on March 3rd, the unavailability of translation updates was due to the migration of the translation repositories and necessary tools from Pagure to the Fedora Forge. It took longer than expected but we are pleased to report this undertaking came finally to the end.
Long time no blog, once again - as always, I'm mostly posting on Mastodon now, so follow there if you're missing the Content. This is a bit big, though, so it goes here!
I was in Prague for Flock 2026 and Brno for Devconf.cz 2026 recently. Didn't have any issues with travel, fortunately. I was in Prague a day early for a Red Hat "face-to-face", which went fine. Had a fairly quiet/jetlagged dinner with Kevin and Tomas on the first night, and a nice dinner with Lenka Segura, Kashyap Chamarthy, Cristian Le, Frantisek Lehman and Laura Barcziova on the second night; most of them I was meeting for the first time in person, which is always good.
Flock 2026
Flock started for real the next day with workshops. I started with "The Future of Fedora Atomic", about how we can reach the goal of all the Atomic images being based on a shared bootc base container, then went to "Forging Fedora Project’s Future With Forgejo". In the afternoon I went to "PR-based Gating for Fedora: Can We Make It Work?", which was about the idea of moving all automated testing/gating to run against dist-git pull requests (instead of mainly against updates, as is the current case).
These were all more "talking shops" than "workshops", really, but they at least mostly produced interesting conversations and concrete ideas. In particular, Cristian and I were able to determine a set of priorities for Fedora CI from the "PR-based gating" session - there was a lot of discussion of potential issues and concerns further down the road of the potential migration, but in the end we found it pretty clear that we need to improve the reliability of the existing tests and pipelines, and the ease of interpreting the results, and that's uncontroversial work that can be done first.
There was also a request from Petr Khartskhaev that we make it possible to run the openQA tests on dist-git pull requests. This had already been requested by Mo Duffy before. I've resisted doing this for all dist-git pull requests because I know at least some would fail when changes to multiple packages need to be grouped and tested together. The update system allows us to group builds into updates, but dist-git does not yet have any way to mark multiple PRs as a logical group for testing/promotion. However, someone suggested a better idea: do it by request, not for all PRs automatically. So I decided to go ahead and do it. Instead of doing another workshop, I hid in the corner of the "Languages in Floss" session and bodged up a working prototype, which is deployed to staging openQA. If you comment /openqa test on a dist-git pull request, tests on it will run in staging openQA. I'm currently working on getting the results reliably reported back to the pull request.
We had a team dinner that evening, again good to meet people and a good mix of work and social chat. At some point in there I met our relatively new RH team member Jaroslav Groman in-person for the first time, which was great - he's been doing excellent work on digging out from under our tooling tech debt and it's great to have him aboard. Peter Sklenar unfortunately wasn't able to come this time.
Day two was session heavy. There was an opening keynote track with Jef's "State of Fedora" address, live Fedora Council and FESCo meetings (effectively), and a Hummingbird talk from Stef Walter. The State of Fedora produced a couple of very talked-about sets of statistics, one showing Fedora (and friends) usage climbing solidly and one showing Fedora contributor numbers declining worryingly. The usage numbers are great, of course - especially the rapidly-growing numbers for KDE and our awesome downstream distro friends (the uBlue-verse, Asahi, Bazzite et. al.) We definitely need to dig into the contributor numbers some more, see what's going on, and whether and what we need to do to reverse the trend. There are a lot of interesting questions about whether it's Red Hatters, community maintainers, or both who are declining, and how this relates to other trends like the CVE tsunami, mushrooming language ecosystems, the rise of Flatpaks / Snaps / AppImages and so on.
The Council and FESCo sessions touched on those topics and several others, though interestingly not the AI Desktop proposal which I was kinda expecting to hear a lot about. I kinda tuned out and hacked through some of them to be honest. Stef's talk gave a good clear overview of Hummingbird - I kinda knew it going in, but it's always good to have it summarized quickly and clearly (at least I thought so).
I unfortunately didn't know about the Lunch and Learns (somehow missed them on the schedule), or else I would have gone to some! But still had plenty of fun/productive lunches with various folks. In particular I met Vít Smolík (smoliicek) in person, which was great. He's been helping out with the data team and infrastructure team and is doing some great work.
In the afternoon I went to the "Packit and Fedora: The CI Story Continues" talk, which was a good summary of the work to rationalize the mess of different systems we have/had testing pull requests. It's much better than it was before. Then I went to "Fedora Server – What you can expect from the next two releases", which was great because it clearly explained the idea of the "Home Server" spinoff which I hadn't really been clear on. And of course it was good to see Peter Boy and Emmanuel Seyman again. Alexander Bokovoy also explained his latest authentication stuff, which as always I didn't entirely understand but filed under "sounds like Alexander has it under control"...
I skipped another session to do some hacking, then went to "The Engineer’s Guide to Design", which was really interesting - I like going to slightly off-the-beaten-path talks. I don't really work on front-end UX stuff a lot, but it was still interesting to hear a perspective from someone who's been both an engineer and a designer on the impedance mismatches that can happen and the basic concepts it's useful for both sides to know about the other. Then I saw "Artifact Signing in Fedora", where Jeremy Cline gave some background and an overview of his ongoing project to rewrite the Fedora signing server, which is badly-needed work that we're really grateful for.
In the evening we had the official party, at a really nice outdoor food court with a reserved space for the conference. The organizers brought over so many appetizers I barely needed to use the meal ticket, but managed to force down some tacos nevertheless. Had a great time chatting with various folks, then later headed to a Belgian beer bar for more drinks with Justin Forbes and several others.
On the final day I started with "The Packager's Guide to openQA Failures" of course - Lukas Ruzicka (my openQA henchman) did a great job covering openQA failure analysis from the perspective of a packager, and I contributed a few notes here and there. We had a good crowd who seemed really interested, which is always great news. After that I saw Kevin Fenzi's "scrapers gotta scrape scrape scrape" talk on all the fun we've been having with scraper networks flooding our infrastructure. I know some but not all of it beforehand, and of course Kevin explained it well and the audience was very engaged. Plus I got to tell my story about the time I thought a dastardly new scraper network had figured out how to evade Anubis, but it turned out that the call was coming from inside the house (i.e. I had done a slightly silly thing in openQA which made it effectively DoS Koji...)
After the coffee break I saw "Fedora Test Days - a11y", which was actually a somewhat wider talk from a couple of RH folks working on accessibility testing about their current testing and future plans. It was really interesting and it was good to be able to speak with them briefly about the possibilities of using openQA for this. I stayed in the same room for "Two Years In: Accelerating Microsoft Contribution to Fedora", where Jeremy Cline, Brian Exelbierd and Reuben Olinsky covered some Microsoft's (much-welcomed) contributions to Fedora and also some stuff about Azure Linux.
After that was "Upgrading Fedora Infrastructure from Nagios to Zabbix" - this migration has been ongoing for a while but was much-needed as a modernization and also a better architecture. I found it very useful as I do have plans to add more detailed monitoring of openQA and the talk was very helpful in letting me know how to get started with that.
After lunch came lightning talks. I had proposed one about "new stuff we did in Fedora CI lately", which kinda overlapped with some of the full-length talks in the end, but it still got a lot of votes, so Cristian Le and I went up second and did a rapid redux of the Packit consolidation work, improved result displays, optimizations and improvements to the generic tests, addition of rmdepcheck and so on. My voice was giving out by this point but we just about got through it. There were a lot of other great talks and everyone managed to come in under time, which was impressive.
After that was a Fedora Mindshare session which I half-followed and half-hacked/dozed through (was starting to get tired at this point!), then the "Fedora’s Contributor Recognition Program" session where much-deserved awards were handed out to Ankur Sinha, Fabio Valentini and Justin Forbes. I was on the voting panel for this so it was great to see the culmination, and the trophies contributed by the Nairobi GNU/Linux Users Group were awesome.
I almost forgot to mention the whole time I was struggling with some sort of wifi driver bug - it seems there was a troublesome AP or something at the hotel which caused my laptop to crash constantly. And the hotel wifi was terrible, and I only had 5GB of data on my phone, so I couldn't really rebase to F44 to avoid it. Lots of fun.
Devconf.cz 2026
That was the end of Flock; things wound down and I had dinner with...some people...somewhere (possibly the third Vietnamese of the trip? Things are getting fuzzy). The next day was a welcome quiet day traveling from Prague to Brno - train and bus, no problem except waiting for the bus was very hot. I stayed at the Hotel Vaka, which I've never been at before, but it's quite nice. The whole event was a bit weird because Moto GP (the motorbike equivalent of Formula 1) moved their Brno race to the same weekend Devconf.cz would usually be on, and took all the hotels, so devconf was hastily moved to Thursday/Friday. Hotels were still hard to get and I only just managed to grab this one at a decent rate. I was able to rebase my laptop finally and stop worrying about wifi crashes, and had a nice quiet pizza dinner at Doe Boy.
So a shortened devconf started with the opening session, then another Hummingbird keynote, this time with Valentin Rothberg as well as Stef Walter. It added a bit of detail compared to Stef's Flock talk, and there wasn't anything else on. Then I saw "OpenShift CI: What if we stopped retesting everything all the time?", which was an interesting talk about the tradeoffs involved in doing automatic retests of complex merge chains in a big project with lots of PRs trying to be merged all the time (OpenShift). It wasn't directly applicable to anything I do, exactly - Fedora updates don't quite map to PRs in a git repo - but in a more general sense it was useful in suggesting methods for thinking about this kind of complex tradeoff and how to measure the impact and efficiency of testing processes.
Next I saw David Duncan's "From Laptop Chaos to Fedora Cloud: Quadlets and Containers", mainly because it was David, but it turned out to be a good talk about a way to make a relatively complex multi-container side project buildable and deployable the same way on your laptop and in The Cloud, using systemd quadlets. I've dealt with this general area before a few times. David made a solid case that quadlets are a good approach, in his usual fun and personable style.
After that I saw Zbigniew's "New security features in systemd" - honestly I missed some of this one, but got the gist of why systemd is trying to modernize various mechanisms here. Then I went to "Beyond the Screen: A Deep Dive into Linux Accessibility for Developers" by Vojtech Polasek, which was one of my highlights of the week - a really good explanation of how computer interaction really works for blind people, and what properties applications should have (and avoid) to make them usable. This is obviously very important for testing purposes.
Next I went to "Stop Looking for the Perfect Prompt: The Design-First Workflow for Coding Agents" to get my corporate mandatory minimum AI Content(tm) - it was actually a pretty good and accessible talk on different approaches to LLM-based feature development. I still don't really use LLM code generation heavily (for a start, I spend so little time actually sitting at a blank screen typing significant amounts of code that it's not really worth worrying about), but it's good to keep up with the latest ideas about how to do this kinda thing. Continuing with the AI theme I took in Tomas Tomecek and Laura Barcziova's "How AI helped us ship updates in a Linux distro", which was a practical talk on the system behind Hummingbird and the actual approach it takes to (sort-of) AI-driven package builds.
After that I think I did some Fedora booth cover for a while. Lukas Ruzicka and Vojtech Trefny were holding the booth down for most of the weekend, but I stopped by and did an hour here and there to give them some relief. It's always a lot of fun chatting to people about Fedora, other distributions or stuff that has nothing to do with Linux at all. Lukas had set up a Framework laptop with a MIDI keyboard attached to show off that it's pretty practical to do audio creation on stock Fedora kernel and audio stack these days; Vojtech and I had absolutely no idea how to use it, so we had lots of fun trying to talk about it to people and eventually telling them to come back when Lukas would be there...
In the evening we had the conference party, which was at the same outdoor swimming pool it's been at for a couple of years(?) now. It's a great venue - you can grab some food and a drink and then relax in the shade under some trees. I wound up sitting round with a really interesting mixed group of folks (Red Hat and non-Red Hat, some big cheeses, some medium-size cheeses and some fresh faced...cheese curds? Help, my metaphor is falling apart) most of the night, it was a great evening. Walked back most of the way to the hotel with Stef Walter, setting the world to rights as is the tradition after a few drinks at conference parties...
On the second day I started with "From Podman to Production: Building Trusted Container Images with Konflux on OpenShift" by Vladimir Sokolenko, which was probably the most understandable and useful Konflux talk I've seen so far. I think I then maybe did a bit more booth cover(?) and some hacking, then wrapped up with a nice three-talk track in the same room - "Identical Testing Environments from Laptop to CI with tmt and Testing Farm" by Cristian and Petr Šplíchal (covering their work to make tests more reproducible from Testing Farm to your local system), "systemd-sysext in Production: What We Learned Extending /usr Without a Package Manager" by Brian Exelbierd and Daniel Zaťovič (a really good retrospective on their experience using sysext in the real world to ship additional / alternative software on Flatcar), and "Local package layering on bootc systems with DNF5" by Evan Goode (explaining his design and plans for providing a convenient, dnf-ish interface to "overlaying" packages on bootc-based installs). I met Evan in person for the first time at the party, and it was great talking to him. I hope his work on this goes well - we really need it for the glorious bootc-based future.
After that was the traditional wrap-up session with the trivia quiz (I won a t-shirt!) and then I said bye to a lot of people and melted off (it was extremely hot) to the train station...to find that my train to Vienna was delayed by nearly an hour. Ah, well. Eventually made it to my hotel in Vienna (which was incredibly nice, just wish I'd stayed there longer...) and had an excellent dinner at Iki (highly recommended if you're in the area). Got in a couple of swims in the nice-but-small hotel pool before and after sleeping, then had a Vienna take on avocado toast (interesting!) for breakfast and headed off to the airport, and that was another trip in the books.
My uncle Tim (We're both Tim Case, he's Tim H. Case, yes, THC, I'm just TC)
just mailed me two more issues of The Hemp Coalitions "Almost a Newsletter"
newsletter.
I just scanned issues 1 and 2 from volume 4, published in 1994, we now have 3 issues up the archive!
I love my uncle Tim a lot. I moved out of NY State with my family when I entered
my early teens. That meant that growing up he and I never got to have the kind
of relationship we wanted to have, that didn't happen in earnest until just
maybe 3 years ago.
Tim H Case is a character. And if you live in the Troy/Albany/Cohoes region of
NY you almost assuredly have encountered my Uncle
Tim.
He's also goes as "Fake Trey" or "Troy Pistachio". He's the Tall skinny ginger
with a pony tail that goes to his hips.
I'm going to show this page to him later and embarrass him �� 💚
Archiving this stuff from his past is one of my ways to connect with him and strengthen our Tim-ly bond 🤜� Tims Forever 🤛�
The full THC collection is available on the archive in this list I made. You can also just search for hemp-coalition-newsletter:
In the weeks leading up to that release (and since then) I have posted
a series of serieses of posts to Mastodon about key new features in
this release, under the
#systemd261
hash tag. In case you aren't using Mastodon, but would like to
read up, here's a list of all 27 posts:
I intend to do a similar series of serieses of posts for the next
systemd release (v262), hence if you haven't left tech Twitter for
Mastodon yet, now is the opportunity. My series for v262 will begin in
a few weeks most likely, under the
#systemd262
hash tag.
Dear testers, we're happy to announce Kiwi TCMS version 16.1!
IMPORTANT:
This is a minor version release which includes security related updates,
several improvements, database migrations, new API methods and updated translations.
I have a 5G modem in my Lenovo x13s and t14s. I run Fedora on them, currently Fedora 44. I have had issues in the past when traveling. The 5G modem works fine when in the US but will not connect to any provider when roaming. It has worked after some time in the UK and Australia, but not in other countries. I use Google Fi for phone service, which allows roaming with the same data allowance as in the US.
After some digging during my current trip, when it wasn’t connecting, I think I have found the issue and a workaround to ensure I can connect. Google Fi uses two networks, T-Mobile in the US and Three UK when roaming. It also uses T-Mobile for roaming. The issue seemed to be that the towers were rejecting the SIM card, attempting to register using T-Mobile’s default APN that seems to be baked into the SIM card as a default profile. The ModemManager logs looked like the following
ModemManager[1603]: <msg> [modem0] 3GPP packet service state changed (unknown -> detached)
ModemManager[1603]: <msg> [modem0] 3GPP packet service state changed (detached -> unknown)
ModemManager[1603]: <msg> [modem0] 3GPP packet service state changed (unknown -> detached)
ModemManager[1603]: <msg> [modem0] 3GPP packet service state changed (detached -> unknown)
The trick that got it to connect was to make a change to the default profile used to connect to the phone tower was to run an mmcli command: “mmcli -m 0 –3gpp-set-initial-eps-bearer-settings=”apn=h2g2,ip-type=ipv4v6” Which forces the sim to use the Google Fi APN and not the T-Mobile one
For quite some time I wanted to explore
openshell. I naively thought it would be
easy to set up on my workstation that has an AMD GPU, together with llama-cpp
as an inference server.
After following the tutorial, I was immediately stuck even with running the gateway in a podman container.
I guess I’m too old for this stuff because I let Claude Code to investigate the problems.
درود بر دوستان، همراهان و اعضای خانواده بزرگ طرفداران فدورا امروز با افتخار پانزدهمین سالگرد تأسیس وبسایت FedoraFans می باشد. پانزده سال پیش، با هدف ترویج فرهنگ نرمافزارهای آزاد و متنباز، آموزش لینوکس فدورا و ایجاد فضایی برای تبادل دانش و تجربه، این وبسایت فعالیت خود را آغاز کرد. آن روزها شاید تصور نمیکردیم که […]
This post discusses tools reluctantly written with AI assistance. If you don’t entertain
using them under any circumstance, and think even reading about them legally compromise
your ability to reimplement them yourselves, stop reading now
Today’s post introduces dbranch, a tool to update a Debian package in unstable, and rebuild downstream branches (currently supports Ubuntu PPAs and stable proposed-updates; backports support could be easily added once I have a package that needs it). Eagle-eyed readers might notice the naming similarity with my previous tool ebranch; and the credit for the name and inspiration eventually came from Jens Petersen’s fbrnch.
I was looking forward to this year’s Flock - Fedora Project Conference. I had to cut my vacation short and return from my river trip a day early.
I arrived in Prague at noon on Sunday, just in time to attend František Lachman’s workshop “PR-based Gating for Fedora: Can We Make It Work?�. We all agreed that we want all contributions to happen through pull requests and only after all tests pass. However, we also realized it is not easy: gating for multi-package PRs will be difficult (unless we have a monorepo). Proven packagers will need special handling (can we work on this later?), and first, we need the new Forgejo—everyone is looking forward to it. Coincidentally, later at Devconf, I spoke to Marcela, who mentioned that SUSE already has Forgejo for all packages and that it does not scale as they expected.
But the important message from Miro was: “we should not force maintainers to use a new workflow; we should make it pleasant and easy to use so they want to use it on their own.�
After this workshop, I checked into my hotel and later returned to the venue. We had a passionate conversation with Aleksandra, Miro, and Karolina during a card game. We then moved with several other people to a nearby pub that served Belgian beer. I had only one glass, but I felt very dizzy and tired, so I returned to the hotel sooner than the rest of the gang.
On Monday, I joined Collin for breakfast, and we discussed the dark corners of RPM building.
Then I moved to the venue and listened to Jef Spaleta’s “State of Fedora� talk. Fedora’s usage is growing, and KDE is working enormously well, but the decline in Fedora’s contributors is accelerating. We have to figure out why and take action, rather than just setting up plans without execution.
The “Fedora Council Strategic Proposals� session was great. Two highlights stood out:
“It’s not the new generation that is different. It’s you who is different,â€� said Aleksandra. “They talk about changing a wallpaper; we are talking about burnout.â€�
“I would not join Fedora if it were stable. I want to improve it.” Jef Spaleta
The subsequent “FESCo Q&A� was less vibrant but provided a great opportunity to learn about members' views. For newcomers, Kevin’s remark that FESCo’s role is sometimes to say “No� and stop things was likely interesting. However, FESCo cannot drive new initiatives; individual contributors must do that.
Then I watched Stef’s talk about Hummingbird; this was not new to me as we closely cooperate on agentic packaging.
I also observed the talk “Packit and Fedora: The CI Story Continues�, as it summarized what my team accomplished with Fedora CI. There were many examples, and the feedback was positive. I appreciated that Matej managed to substitute for Nikola, who got sick at the last minute.
Several ideas in the Q&A highlighted that PRs are not mandatory and that maintainers do not always follow upstream in a timely manner.
I attended “The EU CRA vs. Community: Why You’re Safe, and How Stewards Help�. The CRA was new to me, and the session was packed with concrete information. You may check the most interesting slides in my Mastodon post. The biggest takeaway is that open-source maintainers do not need to worry, but they should be prepared that companies using their software will start email-bombing them in August. There was a nice guide on how to politely reject them.
I took a break and talked to people in the hallway, sharing remarks with my team members. I talked with Kashyap about bootstrapping RISC-V; he was thankful for our support in Copr. We drafted next steps, only to find that Kashyap’s colleague already did that while I was on vacation.
After this, I was quite tired, so I headed to the hotel for a quick nap and shower to get ready for the Official Party, which took place at Manifesto—a local market with various street foods. I met many familiar faces as well as new people.
On Tuesday I listened to Adam’s “RHEL 11 is branching from Fedora 46: What this means for youâ€� talk and appreciated his honesty in answering “I do not knowâ€� to several questions. Later in the hallway, we discussed whether branching RHEL during the Fedora branching phase is ideal, and why we don’t branch during the beta phase instead.
I then moved to Kevin’s talk, “Scrapers Gotta Scrape Scrape Scrape�. This topic was familiar, as we are also fighting scrapers, and Jiri from my team helped package Anubis and its dependencies for Fedora. However, I learned several new things, and the follow-up Q&A was fun. If you think people ranting about scrapers only wrote inefficient web applications, you should definitely see a recording of this talk.
I attended Frederick’s talk, “Machine-readable package lifecycle information in repository metadata�. He spoke about their DNF plugin that can set various End-of-Life dates for different packages. This was extremely helpful, and since we wanted to do something similar in RHEL, I immediately emailed the DNF team to introduce them to Frederick.
After the talk, I bowed to Frederick, as he is reportedly the person behind the migration of AWS Linux to Fedora.
I listened to Microsoft’s talk, “Two Years In: Accelerating Microsoft Contribution to Fedoraâ€�. It was interesting to see how much Microsoft uses Fedora. The highlight was that the presenters were from different teams within Microsoft and were largely unaware of each other’s work.
I then talked to people in the corridor, including Bex, who introduced me to two students from Jihlava interested in a high school internship.
The highlight was definitely the lightning talks. They were strictly 5 minutes long (including notebook setup). I learned about current Lenovo support for Linux, how Miro sped up the last Python mass rebuild, and I reported on the current status of the SPDX migration, noting that the next steps will proceed without me. Fortunately, Max started a SIG that wants to take over the work. I shared some information with him that didn’t fit into the lightning talk. Jiri presented his achievement of packaging Goose for Fedora and even provided a live demo!
By this point, I was quite tired, so I passively watched the presentation of the Contributor Recognition Awards. Then, I went into the city to meet a friend, and we attended the theater performance Tahle země je naše.
Tip: If you want to see any mentioned talk, you can find it in the schedule and then rewind to the specific time in the Streams. The edited and cut talks are usually available weeks later on Fedora’s channel.
DevConf
DevConf CZ is huge even. With over one thousand participants and eleven tracks - it is huge. As this is a conference in my hometown I volunteered to help organizers: I chaired one of the rooms and acted as a fire marshall. That includes overseeing A/V tech. Help speakers to connect to video and mic. Make sure they do not run with that. Remind them the time.
This year, I chose a room with Lightning talks. There was 15 minutes for each talk and 5 minutes for a break. And it was a blast!
I chaired the Thursday morning and Friday afternoon. One of the best delivered talks was from new junior who was speaking for the first time - yet she overperformed more senior people.
“AI accelerated learning. Mentorship directed it. Real systems grounded it.” Kaja Prokopova @ “From Sysadmin to Software Engineer: A Non-Traditional Path into Tech”
Anežka Müller speaks about how she organizes a small one-day, one-track conference, Python Pizza. You can use her recipe for free https://docs.python.pizza/
James Freeman with his theory about technology dopamine culture.
Jan Jurca spoke about tests on the filesystem that produce different results if you use the filesystem for some time. You can artificially simulate the usage of filesystem and then run the benchmarks using Filestorm https://github.com/janjurca/Filestorm
See the interesting slides.
I did a small cameo at lightning talk by my student Peter Stefunko in his talk “From SBOM to Dependency Stacks: Making Software Structure Visible“ where he tries to visualize the state of the operating system using famous XKCD comics “Dependency�. You can check his work at github.com/peter-stefunko/rpm2xkcd2347.
I did not attend Thursday’s party as we had an anniversary with my wife and preferred my wife over all of you. 🙂
I met many old faces, former colleagues. And the biggest surprise was the booth of Free Software EU where I found the Czech edition of the book Ada & Zangemann that I helped to translate. I did not know it was already printed - that was because the print was finished that morning. I then called Tomas Stary who took the work from me and who I never met - only to find that he is standing beside me in the queue for ice cream 🙂
Mathias post about the new print https://mastodon.social/@kirschner/116770321504331386
Half of the batch. Fresh from print.
Later we discussed with Tomas, his publisher and Lucie from RH additional steps to advertise the book.
Last week I had to extend complicated, unfamiliar Helm chart. While
I've discussed approach with my carbon-based coworker, actual
editing and extending was done by Claude Code.
Refactors and renamings were tedious, but Claudius did them in no time.
During the review we decided to significantly change the way
chart is organised. Claude executed the changes perfectly.
If I had to fully understand the working of the chart, it would
have taken me a good part of the week. Making the changes – another
day or two. Significant rework midway – I'd probably be too demotivated to
do it.
With AI assistant, I have finished work in two days. Tested, simplified,
cleaned up.
But I have no more skills than I had before. I do not understand this
Helm chart much better. I've spotted a thing or two during the review,
but in no way I have a fuller comprehension. AI let me borrow expertise without acquiring it.
Next time when I'll have to work on this chart, I will use Claude again.
I've got softly locked-in in using AI assistant to work. And I'm not happy with that.
Now, my employer sees this as an acceptable tradeoff. Paid for some tokens,
unlocked couple of my pricy senior-level hours to do other stuff. It balances.
Subsidising Scam Altman and his ilk is a money well spent from this perspective.
We are at the point where we offload more work to so-called AI. Those
are just tools. You know what more primitive tools we had before? Assemblers.
Then compilers. No one writes machine code by hand anymore. Maybe someone
despairs because of it, but people commonly writing binaries are more likely
to be dead by now.
No one treats high level compilers as fad and stuff kids these days do. It's
just a tool, expected to work and dissappering into the background.
There's one important difference. We do not have to pay for the compilers,
thanks to work of the GNU Project last century (gcc) and Apple more recently (llvm/clang).
But at this point we are paying for tokens. I expect that as we
cannot fathom working with any codebase without a compiler now, a LLM-driven
assistant will be required to tackle bigger projects in near future.
To be free, we need to be able to run assistants at reasonable cost.
Free is reasonable. Not paying through the nose for electricity is reasonable.
We can hope for good quality chinese models to be available for free.
We need a free toolkit revolution again. It was GNU Compiler Collection
for the previous generation. Would it be Kimi now?
And we need the proprietary AI bubble to pop and rationality to return.
This is an independent, censorship-resistant site run by volunteers. This site and the blogs of individual volunteers are not officially affiliated with or endorsed by the Fedora Project.



















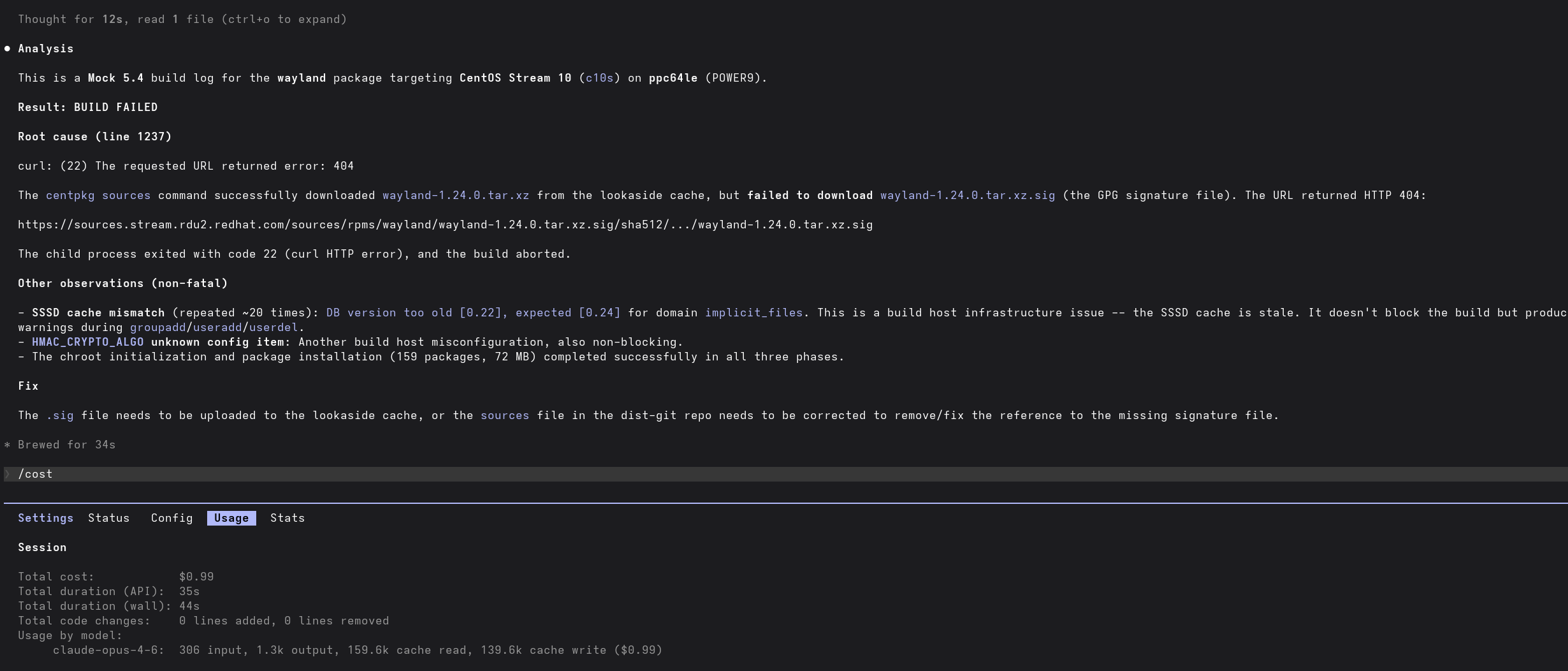
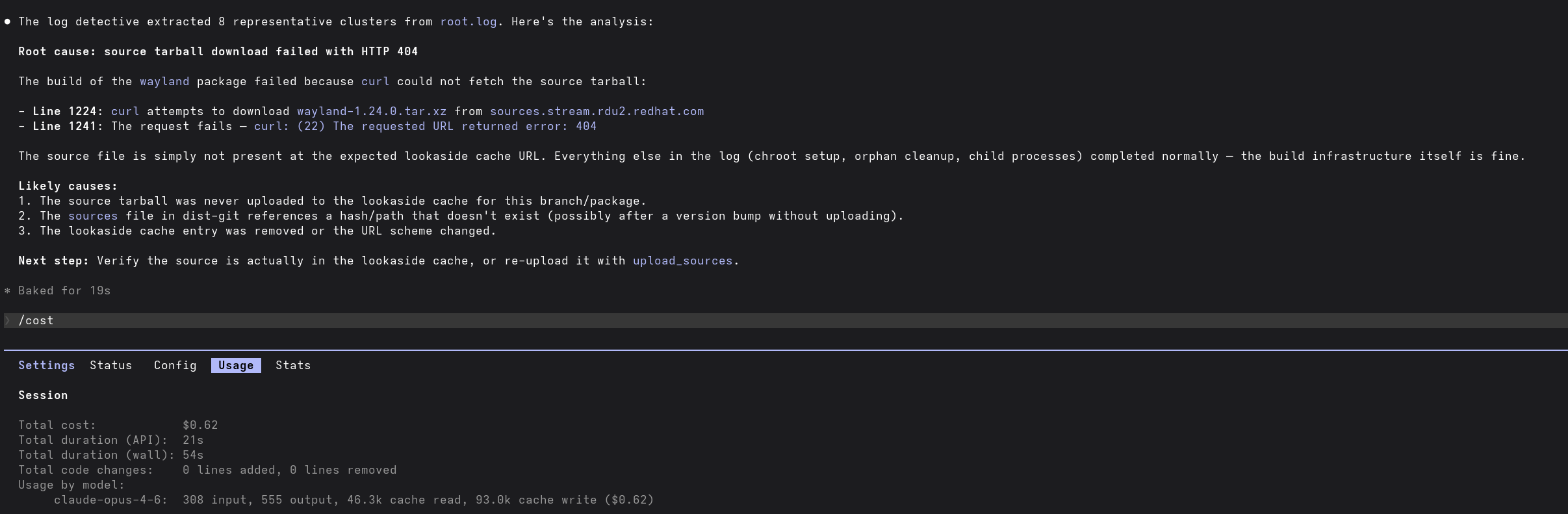








 “AI accelerated learning. Mentorship directed it. Real systems grounded it.” Kaja Prokopova @ “From Sysadmin to Software Engineer: A Non-Traditional Path into Tech”
“AI accelerated learning. Mentorship directed it. Real systems grounded it.” Kaja Prokopova @ “From Sysadmin to Software Engineer: A Non-Traditional Path into Tech” Petr KaÅ¡ka spoke about detecting malicious prompts. You can attack your model using
Petr Kaška spoke about detecting malicious prompts. You can attack your model using  Anežka Müller speaks about how she organizes a small one-day, one-track conference, Python Pizza. You can use her recipe for free
Anežka Müller speaks about how she organizes a small one-day, one-track conference, Python Pizza. You can use her recipe for free  James Freeman with his theory about technology dopamine culture.
James Freeman with his theory about technology dopamine culture. Half of the batch. Fresh from print.
Half of the batch. Fresh from print.